
Как обойти капчу на примере самого используемого в мире плагина для WordPress Really Simple Captcha. Обход капчи на python довольно тривиальная задача, но получится ли это сделать за 15 минут?
Капча (CAPTCHA) — надоедливая картинка с текстом, которую надо ввести, чтобы попасть на сайт. Капчу придумали чтобы роботы не могли автоматически заполнять формы, и чтобы владельцы сайта были уверены, что пользователь — человек. С развитием машинного обучения и нейронных сетей, ее зачастую стало довольно просто обойти.
Я прочел отличную книгу: Deep Learning for Computer Vision with Python, которую написал Adrian Rosebrock. В этой книге Адриан описывает способ, которым он взломал капчу на сайте E-ZPass New York используя машинное обучение:
У Адриана не было доступа к исходному коду, генерирующему капчу. Чтобы обучить модель, ему пришлось скачать тысячи картинок и вручную разметить все надписи.
Но предположим, что мы хотим обойти капчу, к исходному коду которой у нас есть доступ.
Я зашел на WordPress.org Plugin Registry и ввел в поиске “captcha”. Первый результат назывался “Really Simple CAPTCHA” и установлен более миллиона раз.
И самое крутое — он с открытыми исходниками! Раз у нас есть алгоритм, генерирующий картинку, его, должно быть, не сложно обойти. Чтобы было сложнее, ограничим себе время. Можно ли уложиться в 15 минут? Давайте попробуем!
Важное замечание: Это ни в коем случае не критика плагина “Really Simple CAPTCHA” или его автора. Сам автор указал, что плагин более не является надежным и рекомендует использовать что-нибудь другое. Это просто небольшой интересный челлендж. Если вы один из того миллиона пользователей, установивших его, то возможно вам стоит сменить данный плагин на что-нибудь другое 🙂
Челлендж: обход капчи на Python
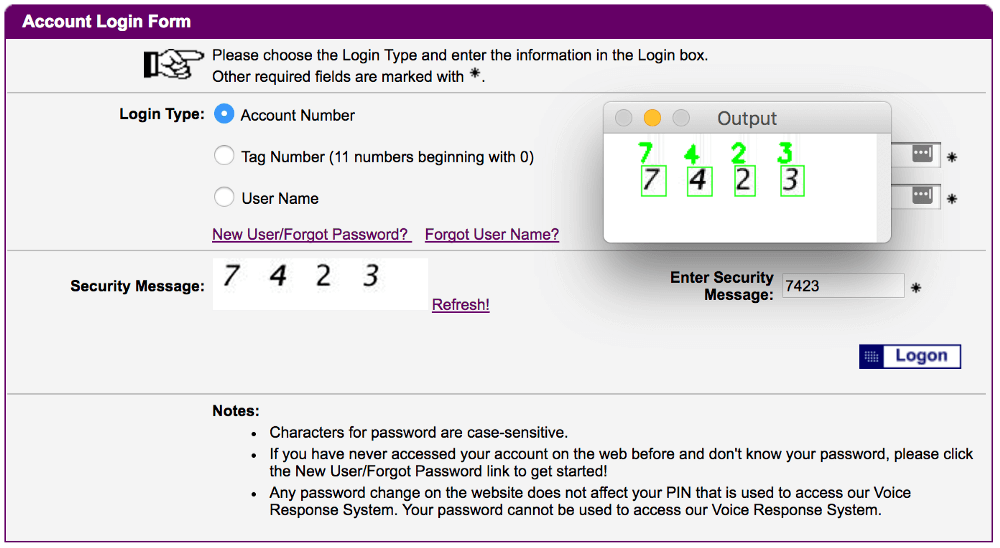
Для начала посмотрим на изображения, создаваемые Really Simple CAPTCHA. На демке видим это:

Итак, капча состоит из четырех букв. Убедимся в этом, посмотрев исходники:
public function __construct() {
/* Characters available in images */
$this->chars = 'ABCDEFGHJKLMNPQRSTUVWXYZ23456789';
/* Length of a word in an image */
$this->char_length = 4;
/* Array of fonts. Randomly picked up per character */
$this->fonts = array(
dirname( __FILE__ ) . '/gentium/GenBkBasR.ttf',
dirname( __FILE__ ) . '/gentium/GenBkBasI.ttf',
dirname( __FILE__ ) . '/gentium/GenBkBasBI.ttf',
dirname( __FILE__ ) . '/gentium/GenBkBasB.ttf',
);
Да, действительно капча создается случайным образом из четырех букв или цифр с разными шрифтами. Символы “O”, “0”, “I”, “1” не используются, чтобы пользователь не путался. Остается 32 символа, которые нужно распознать. Не проблема!
Прошло: 2 минуты
Набор инструментов для решения капчи
Перед тем, как решать задачу, перечислим инструменты, которыми мы будем пользоваться:
Python 3
Python — простой и мощный язык программирования с отличными библиотеками для машинного обучения и машинного зрения.
OpenCV
Популярная библиотека для обработки изображений с поддержкой алгоритмов машинного зрения. Мы будем использовать ее для предварительной обработки капчи. OpenCV написана на C++, но все ее функции вызываются из питона, чем мы и будем пользоваться.
Keras
Фреймворк для машинного обучения, написанный на питоне. С его помощью легко строить, обучать и использовать нейронные сети. Требует минимального количества кода.
TensorFlow
Гугловская библиотека для машинного обучения. Мы будем пользоваться только Keras, но сам Keras в качестве бэкенда использует TensorFlow, поэтому его тоже придется установить.
Итак, обратно к задаче!
Создаем датасет
Чтобы собрать любую модель машинного обучения, требуются обучающие данные. Нам понадобятся данные, выглядящие следующим образом:

Так как у нас есть исходный код плагина, создающего капчу, мы можем его использовать, чтобы нагенерировать 10,000 изображений, и для каждого будет известна расшифровка.
Пару минут повозившись с кодом и добавив в него простой цикл ‘for’, я получил папку с обучающими данными — 10,000 PNG файлов, в названии которых указан правильный ответ:

В этом и только в этом месте я не дам вам рабочий пример кода. Мы делаем это в образовательных целях, и мне не хочется, чтобы вы заспамили реальные сайты, работающие на WordPress. Вместо этого, я дам ссылку на 10,000 изображений, сделанных мной, чтобы вы могли повторить мой результат.
Прошло: 5 минут
Обход капчи на python: упрощаем задачу
Теперь, когда есть обучающие данные, мы могли бы их использовать напрямую, обучив по ним нейросеть:
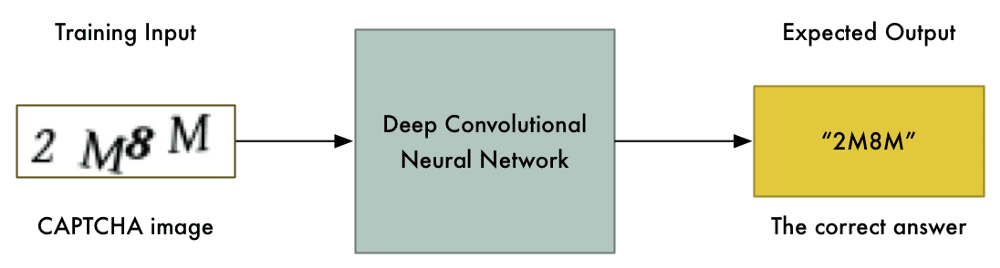
С достаточным количеством данных, этот подход мог бы даже сработать. Но можно сделать решение капчи на python проще. Чем проще задача, тем меньше нам понадобится обучающих данных и вычислительных ресурсов, чтобы ее решить. У нас ведь всего лишь 15 минут!
К счастью, капча состоит всего из четырех символов. Если как-нибудь разделить ее так, чтобы каждая буква была отдельным изображением, то можно будет обучить нейросеть распознавать по одному символу за раз:
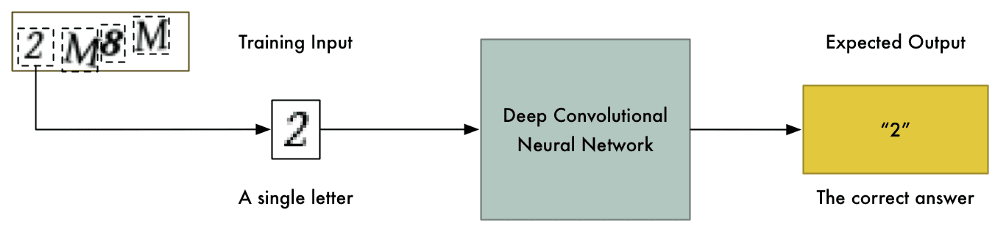
У меня нет времени разрезать каждую из 10,000 картинок в фотошопе. Это бы заняло несколько дней, а у меня осталось всего 10 минут. И нельзя просто автоматически разделить все картинки на 4 одинаковых куска. Потому что алгоритм задает символам случайное горизонтальное положение:
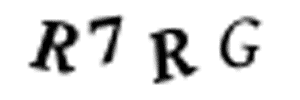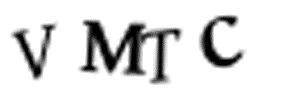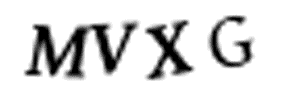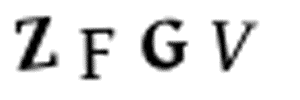
Символы сдвинуты случайным образом, чтобы изображение было сложнее разделить.
К счастью, это всё же можно автоматизировать. При обработке изображений часто приходится находить связные области из пикселей одного цвета. Границы таких областей называют контурами. В OpenCV есть встроенная функция findContours(), которую мы используем, чтобы найти связные области.
Итак, начнем с изображения капчи:
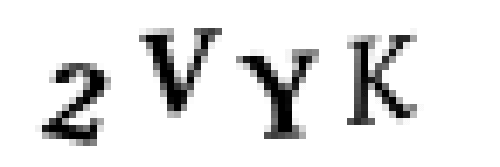
Преобразуем изображение в бинарное (это называется thresholding), чтобы было легче найти связные области:
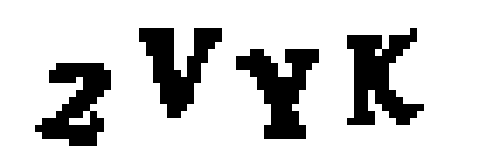
Далее, используем функцию findContours(), чтобы выделить связные группы пикселей, состоящие из одного цвета:
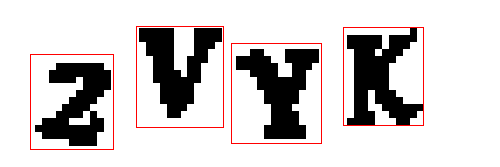
Теперь, нужно просто сохранить каждый прямоугольник как отдельное изображение. И, так как мы знаем последовательность символов в каждом изображении, можно подписать каждый прямоугольник своим символом при сохранении.
Погодите-ка! Тут есть проблемка! Буквы в капче иногда накладываются друг на друга:
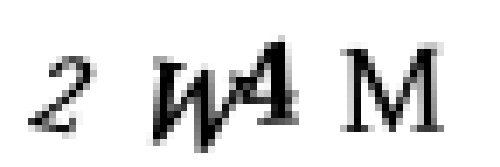
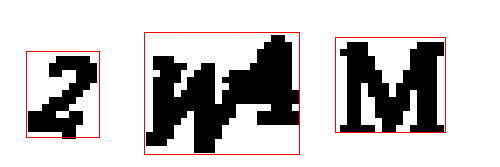
Если проблему не решить, то у нас будут плохие обучающие данные. Это нужно исправить, потому что с такими данными мы обучим модель распознавать эти две слившиеся буквы как одну.
Простой выход из этой ситуации сказать, что если какой-то прямоугольник в ширину сильно больше, чем в высоту, то это нужно считать двумя буквами. В этом случае, прямоугольник можно просто разрезать посередине и считать, что это два прямоугольника:
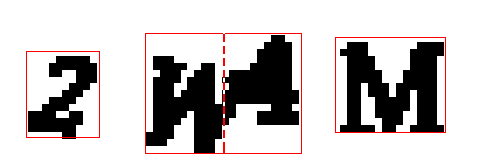
Мы разделим пополам все прямоугольники, ширина которых сильно превышает высоту, и будем считать их за две буквы. Способ слегка “химический”, но с этими капчами работает.
Теперь, когда у нас есть способ извлекать из капчи отдельные буквы, давайте прогоним наш алгоритм через весь датасет. Цель — получить много вариантов написания для каждой буквы. Каждую букву можно сохранять в отдельную папку.
Вот так выглядит моя папка с буквой “W” после того, как я запустил свой алгоритм:

Некоторые буквы “W”, вытащенные из наших 10,000 изображений. У меня всего получилось 1,147 разных “W”.
Прошло: 10 минут…
Создаем и обучаем нейросеть
Так как нам нужно всего лишь распознавать одну букву или цифру, нейросеть со сложной архитектурой не потребуется. Распознавание символов — это гораздо более простая задача, чем распознавание сложных изображений, к примеру, кошек и собак.
Будем использовать простую сверточную нейросеть с двумя сверточными (convolutional) слоями и двумя полносвязными (dense):

# Build the neural network! model = Sequential() # First convolutional layer with max pooling model.add(Conv2D(20, (5, 5), padding="same", input_shape=(20, 20, 1), activation="relu")) model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2))) # Second convolutional layer with max pooling model.add(Conv2D(50, (5, 5), padding="same", activation="relu")) model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2))) # Hidden layer with 500 nodes model.add(Flatten()) model.add(Dense(500, activation="relu")) # Output layer with 32 nodes (one for each possible letter/number we predict) model.add(Dense(32, activation="softmax")) # Ask Keras to build the TensorFlow model behind the scenes model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
Теперь можно обучать нейросеть!
# Train the neural network model.fit(X_train, Y_train, validation_data=(X_test, Y_test), batch_size=32, epochs=10, verbose=1)
После 10 прогонов по всему обучающему набору, мы достигаем точности почти в 100%. В начале мы ставили задачу обойти капчу на python. И мы это сделали!
Прошло: 15 минут (фух!)
Используем обученную модель для обхода капчи
Теперь, когда нейросеть обучена, ее можно использовать для взлома капчи:
- Взять изображение капчи с сайта, который использует этот плагин.
- Разбить картинку на четыре части, на каждой из которых по одному символу.
- Прогнать каждую часть через нейросеть.
- Использовать выданные нейросетью буквы, чтобы решить капчу.
- PROFIT!
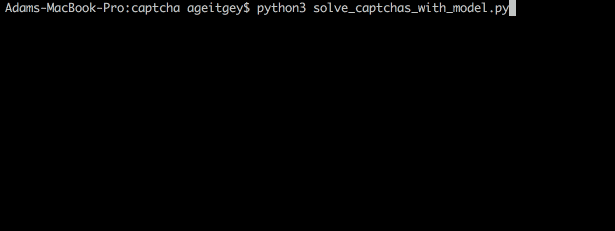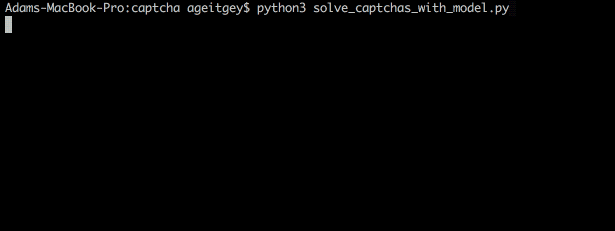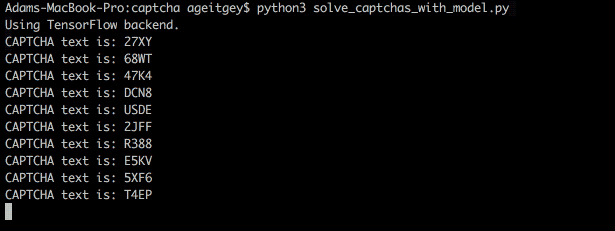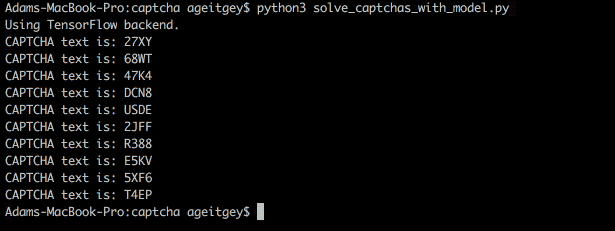
Вот так выглядит расшифровка реальной капчи:

А в командной строке вот так:
Попробовать самому!
Если хотите попробовать сами, то возьмите код здесь. Он включает 10,000 картинок и код для каждого шага в этой статье. Инструкция к запуску в файле README.md.
Но если хочется вникнуть и понять, что делает каждая строчка кода, советую купить книгу Deep Learning for Computer Vision with Python. Она содержит более детальное объяснение и кучу разобранных примеров. Это единственная книга из тех что я видел, в которой объясняется и как это работает, и как это использовать, чтобы решать реальные и сложные задачи. Рекомендую!
Разгадать капчу с помощью AI поможет сервис Capsolver.






Привет автор! не хватает компонент в вашей алгоритме «model_labels.dat»
labels. dat можешь с демки вытянуть
Там нету