
Рекуррентная нейронная сеть (Recurrent Neural Network, RNN) — популярный вид нейронных сетей, используемых в обработке естественного языка (NLP). Рекуррентная нейросеть оценивает произвольные предложения на основе того, насколько часто они встречались в текстах. Это дает меру грамматической и семантической корректности, что позволяет использовать такие модели для перевода текстов. Кроме того, такие модели генерируют новый текст. Обучение модели на поэмах Шекспира позволит генерировать новый текст, похожий на Шекспира.
Что такое рекуррентная нейронная сеть?
Идея RNN заключается в последовательном использовании информации. В традиционных нейронных сетях подразумевается, что все входы и выходы независимы. Но для многих задач это не подходит. Если вы хотите предсказать следующее слово в предложении, лучше учитывать предшествующие ему слова. RNN называются рекуррентными, потому что они выполняют одну и ту же задачу для каждого элемента последовательности, причем выход зависит от предыдущих вычислений. Еще одна интерпретация RNN: это сети, у которых есть «память», которая учитывает предшествующую информацию. Теоретически рекуррентная нейронная сеть может использовать информацию в произвольно длинных последовательностях, но на практике она ограничена лишь несколькими шагами (подробнее об этом позже).
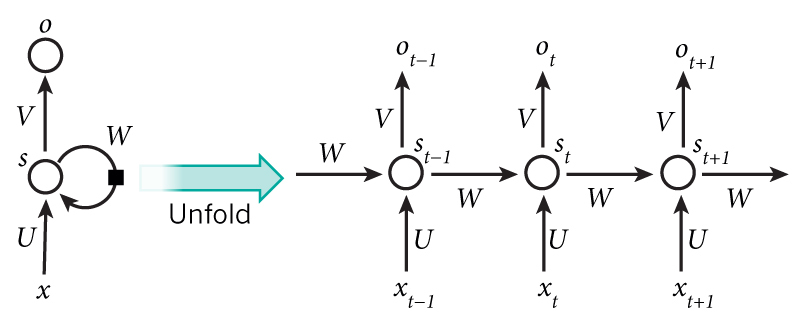
На диаграмме выше показано, что RNN разворачивается в полную сеть. Разверткой мы просто выписываем сеть для полной последовательности. Например, если последовательность представляет собой предложение из 5 слов, развертка будет состоять из 5 слоев, по слою на каждое слово. Формулы, задающие вычисления в RNN следующие:
- x_t — вход на временном шаге t. Например x_1 может быть вектором с одним горячим состоянием (one-hot vector), соответствующим второму слову предложения.
- s_t — это скрытое состояние на шаге t. Это «память» сети. s_t зависит, как функция, от предыдущих состояний и текущего входа x_t: s_t=f(Ux_t+Ws_{t-1}). Функция f обычно нелинейная, например tanh или ReLU. s_{-1}, которое требуется для вычисление первого скрытого состояния, обычно инициализируется нулем (нулевым вектором).
- o_t — выход на шаге t. Например, если мы хотим предсказать слово в предложении, выход может быть вектором вероятностей в нашем словаре. o_t = softmax(Vs_t)
Несколько заметок:
- Можно интерпретировать s_t как память сети. s_t содержит информацию о том, что произошло на предыдущих шагах времени. Выход o_t вычисляется исключительно на основе «памяти» s_t. На практике все немного сложнее: s_t не может содержать информацию слишком большого количества предшествующих шагов;
- В отличие от традиционной глубокой нейронной сети, которая использует разные параметры на каждом слое, RNN имеет одинаковые (U, V, W) на всех этапах. Это отражает тот факт, что мы выполняем одну и ту же задачу на каждом шаге, используя только разные входы. Это значительно уменьшает общее количество параметров, которые нам нужно подобрать;
- Диаграмма выше имеет выходы на каждом шаге, но, в зависимости от задачи, они могут не понадобиться. Например при определении эмоциональной окраски предложения, целесообразно заботиться только о конечном результате, а не о окраске после каждого слова. Аналогично, нам может не потребоваться ввод данных на каждом шаге. Основной особенностью RNN является скрытое состояние, которое содержит некоторую информацию о последовательности.
Где используют рекуррентные нейросети?
Рекуррентные нейронные сети продемонстрировали большой успех во многих задачах NLP. На этом этапе нужно упомянуть, что наиболее часто используемым типом RNN являются LSTM, которые намного лучше захватывают (хранят) долгосрочные зависимости, чем RNN. Но не волнуйтесь, LSTM — это, по сути, то же самое, что и RNN, которые мы разберем в этом уроке, у них просто есть другой способ вычисления скрытого состояния. Более подробно мы рассмотрим LSTM в другом посте. Вот некоторые примеры приложений RNN в NLP (без ссылок на исчерпывающий список).
Языковое моделирование и генерация текстов
Учитывая последовательность слов, мы хотим предсказать вероятность каждого слова (в словаре). Языковые модели позволяют нам измерить вероятность выбора, что является важным вкладом в машинный перевод (поскольку предложения с большой вероятностью правильны). Побочным эффектом такой способности является возможность генерировать новые тексты путем выбора из выходных вероятностей. Мы можем генерировать и другие вещи, в зависимости от того, что из себя представляют наши данные. В языковом моделировании наш вход обычно представляет последовательность слов (например, закодированных как вектор с одним горячим состоянием (one-hot)), а выход — последовательность предсказанных слов. При обучении нейронной сети, мы подаем на вход следующему слою предыдущий выход o_t=x_{t+1}, поскольку хотим, чтобы результат на шаге t был следующим словом.
Исследования по языковому моделированию и генерации текста:
- Word2Vec: как работать с векторными представлениями слов
- NLP Architect от Intel: open source библиотека моделей обработки естественного языка
Машинный перевод
Машинный перевод похож на языковое моделирование, поскольку вектор входных параметров представляет собой последовательность слов на исходном языке (например, на немецком). Мы хотим получить последовательность слов на целевом языке (например, на английском). Ключевое различие заключается в том, что мы получим эту последовательность только после того, как увидим все входные параметры, поскольку первое слово переводимого предложения может потребовать информации всей последовательности вводимых слов.

Распознавание речи
По входной последовательности акустических сигналов от звуковой волны, мы можем предсказать последовательность фонетических сегментов вместе со своими вероятностями.
Генерация описания изображений
Вместе со сверточными нейронными сетями RNN использовались как часть модели генерации описаний неразмеченных изображений. Удивительно, насколько хорошо они работают. Комбинированная модель совмещает сгенерированные слова с признаками, найденными на изображениях.
Обучение RNN
Обучение RNN аналогично обучению обычной нейронной сети. Мы также используем алгоритм обратного распространения ошибки (backpropagation), но с небольшим изменением. Поскольку одни и те же параметры используются на всех временных этапах в сети, градиент на каждом выходе зависит не только от расчетов текущего шага, но и от предыдущих временных шагов. Например, чтобы вычислить градиент при t = 4, нам нужно было бы «распространить ошибку» на 3 шага и суммировать градиенты. Этот алгоритм называется «алгоритмом обратного распространения ошибки сквозь время» (Backpropagation Through Time, BPTT). Если вы не видите в этом смысла, не беспокойтесь, у нас еще будет статья со всеми кровавыми подробностями. На данный момент просто помните о том, что рекуррентные нейронные сети, прошедшие обучение с BPTT, испытывают трудности с изучением долгосрочных зависимостей (например, зависимость между шагами, которые находятся далеко друг от друга) из-за затухания/взрывания градиента. Чтобы обойти эти проблемы, существует определенный механизм, были разработаны специальные архитектуры PNN (например LSTM).
Модификации RNN
На протяжении многих лет исследователи разрабатывали более сложные типы RNN, чтобы справиться с некоторыми из недостатков классической модели. Мы рассмотрим их более подробно в другой статье позже, но я хочу, чтобы этот раздел послужил кратким обзором, чтобы познакомить вас с классификацией моделей.
Двунаправленные рекуррентные нейронные сети (Bidirectional RNNs) основаны на той идее, что выход в момент времени t может зависеть не только от предыдущих элементов в последовательности, но и от будущих. Например, если вы хотите предсказать недостающее слово в последовательности, учитывая как в левый, так и в правый контекст. Двунаправленные рекуррентные нейронные сети довольно просты. Это всего лишь два RNN, уложенных друг на друга. Затем выход вычисляется на основе скрытого состояния обоих RNN.
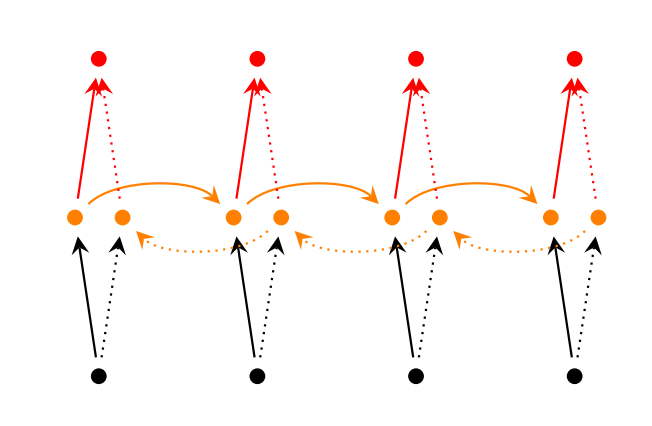
Глубинные рекуррентные нейронные сети похожи на двунаправленные RNN, только теперь у нас есть несколько уровней на каждый шаг времени. На практике это даст более высокий потенциал, но нам также потребуется много данных для обучения.
Сети LSTM довольно популярны в наши дни, мы кратко говорили о них выше. LSTM не имеют принципиально отличающейся архитектуры от RNN, но они используют другую функцию для вычисления скрытого состояния. Память в LSTM называется ячейками, и вы можете рассматривать их как черные ящики, которые принимают в качестве входных данных предыдущее состояние h_ {t-1} и текущий входной параметр x_t. Внутри, эти ячейки, решают, какую память сохранить и какую стереть. Затем они объединяют предыдущее состояние, текущую память и входной параметр. Оказывается, эти типы единиц очень эффективны в захвате (хранении) долгосрочных зависимостей.








