Google представила модель SimVLM, генерирующую текст по одному изображению. Возможности SimVLM включают формирование простого описания предложения, завершение предложения по нескольким первым словам и ответы на вопросы об объектах на изображении.
Модели визуального языка могут использоваться, например, для генерации субтитров к видеозаписям с описанием сцены. Этот подход направлен на изучение единого пространства объектов на основе как визуальных, так и языковых входных данных, а не на изучение двух отдельных пространств объектов.
Модель SimVLM обучалась на датасете ALIGN, содержащем около 1,8 млрд пар изображение-текст, и имеет архитектуру трансформера.
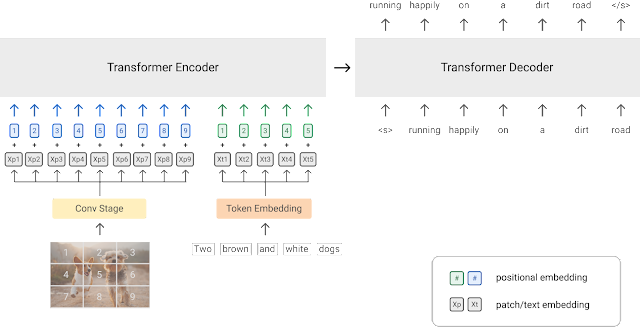
После обучения модель оказалась способна генерировать текст различных типов по одному изображению. В частности, SimVLM умеет генерировать простое описание изображения, завершать предложение по нескольким первым словам и отвечать на вопросы об объектах на изображении.
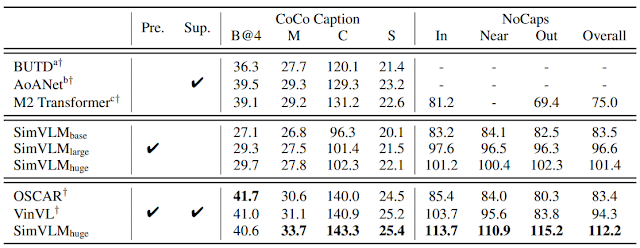
Сравнение с аналогичными моделями на бенчмарках COCO Caption и NoCaps показало, что SimVLM может достигать сравнимые показатели точности несмотря на отсутствие обучения с учителем, как в других моделях: