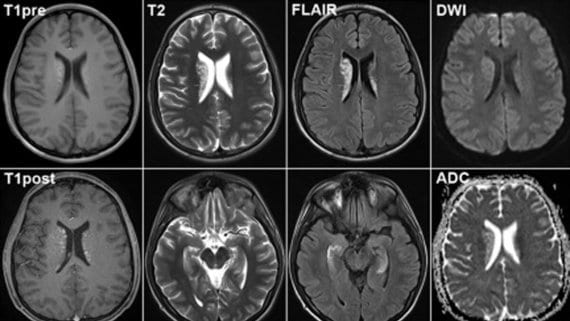
Преобразование «image-to-image» – метод отображения фото из исходного домена в целевой. Метод включают в себя раскраску изображений, восстановление со сверхвысоким разрешением, перенос стиля, адаптацию домена и увеличение плотности данных. Для большинства подходов требуется, чтобы данные доменов были спарены или согласованы друг с другом, как, например, при переносе спутниковых снимков на топографические карты. Как следствие, возникают сложности с применением алгоритма, вплоть до невозможности решения некоторых задач.
Неконтролируемые методы, такие как DiscoGAN и CycleGAN, преодолевают проблему путем вычисления циклических потерь, наличие которых побуждает целевой домен точно восстанавливаться в исходный при выполнении обратного преобразования. Входное изображение подается в архитектуру нейронной сети, подобную связке «кодер-декодер», называемую генератором, которая выполняет преобразование изображения. Затем выходной результат подается на дискриминатор, который пытается определить, правильно ли было отображено исходное изображение. Однако эти подходы ограничены неспособностью системы действовать только на определенные участки изображения. В неконтролируемом случае, когда домены не сопряжены или не согласованы, сеть должна дополнительно определить, какие области изображений предназначены для преобразования.

Например, из рисунка 1 видно, что для корректного перехода между доменами лошади и зебры нужно, чтобы сеть находила и изменяла только те участки изображений, на которых изображены животные. Задача является сложной для существующих алгоритмов, даже если они, как PatchGAN, вычисляют локализованные потери, поскольку сама сеть не имеет явного механизма внимания. Вместо этого алгоритмы обычно минимизируют расхождение между изображением в исходном и целевом доменах, учитывая все пиксели. Для преодоления ограничения на эффективность работы алгоритма применяется новый подход, в рамках которого минимизируется расхождение лишь информативной части изображения (в двух доменах) без учета фона.
Архитектура
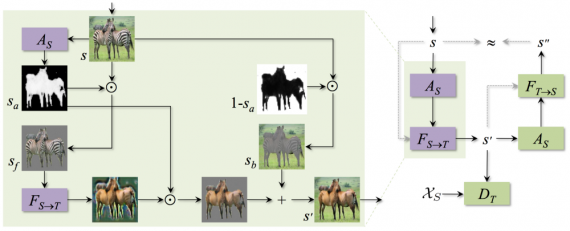
Целью преобразования изображения является приближенное вычисление отображения F(S→T) из домена исходного изображения S в домен целевого изображения Т, основанное на независимых выборках X(S) и X(T), таких, что распределение отображенных точек F(S→T) (XS) совпадает с распределением вероятности P(T) целевого изображения. Для обучения передаточной сети F(S→T) требуется наличие дискриминатора D(T), который пытается обнаружить в образцах X(T) преобразованные изображения. Для согласованности циклов обратное отображение F(T→S) и соответствующий дискриминатор D(S) обучаются одновременно. Для этого требуется решение двух одинаково важных задач:
- расположение областей для отображения на каждом изображении, и
- применение правильного отображения к данным областям.
Для этого были разработаны две сети внимания A(S) и A(T), которые осуществляют выбор областей для преобразования путем максимизации вероятности того, что дискриминатор совершает ошибку.
Генератор механизма внимания
Исходные изображения подаются в сеть внимания A(s) для выполнения отображения s(a)=AS(s). Получаемое изображение s’ имеет вид:
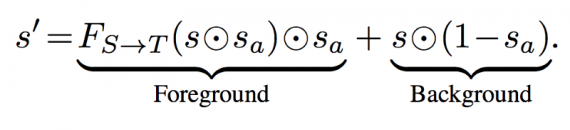
«Приоритетный» объект s(f) формируется путем поэлементного умножения в каждом канале RGB: s(f)=s(a)⊙s. Затем s(f) подается в генератор F(S→T), который отображает его в целевой домен Т. Затем к полученному результату добавляется фоновое изображение s(b) =(1-s(a))⊙s.
Функция потерь. Потери определяются состязательной частью энергии:
![]()
Дискриминатор механизма внимания
Учет функции потерь приводит к увеличению эффективности нашего алгоритма. Во-первых, он обеспечивает сохранение информации (например, положения объекта) в задействованных областях формирующегося изображения. Во-вторых, четкие (сходящиеся к бинарным) отображения имеют больший приоритет, так как потери незадействованных областей на одном цикле всегда будут равны нулю.
Полная энергия вычисляется путем комбинирования состязательных и циклических потерь как для исходного, так и для целевого доменов:
![]()
При непрерывном отображении внимания дискриминатор может получать на вход «дробные» значения пикселей, которые могут быть близки к нулю в начале обучения. В то время как генератор выигрывает от возможности смешивания пикселей на границах объектов, умножение реальных изображений на эти дробные значения приводит к тому, что дискриминатор начинает считать, что серый цвет является «реальным» (т. е. мы сдвигаем результат в точку 0 нормированной области значений яркости пикселя [-1 , 1]). Обученное отображение внимания для дискриминатора имеет вид:

Таким образом, улучшенное выражение для состязательной части энергии L(adv) имеет вид:
![]()
Результат
Для оценки качества работы предложенного метода преобразования изображений использовался принцип Fréchet Inception Distance (FID). FID вычисляет расстояние Фреше между функциями, которые сопоставляются реальному и сгенерированному изображениям. Такие функции извлекаются из последнего скрытого уровня архитектуры FID. Наш метод позволяет достичь наименьшего значения FID во всех случаях, кроме одного. Следующим по эффективности, после нашего, является метод CycleGAN. UNIT достигает второго наименьшего значения FID, что означает, что предположение о скрытых параметрах в данном случае является уместным. Код доступен по ссылке.

Современные неконтролируемые методы преобразования изображения в изображение могут отображать как нужные, так и ненужные (фоновые) части изображения. Как следствие, генерируемые изображения не выглядят реалистично, так как фон и приоритетный объект обычно совмещаются ненадлежащим образом. Включив механизм внимания в неконтролируемое преобразование изображения в изображение, наш подход демонстрирует значительное улучшение качества генерируемых изображений.

Превращение яблок в апельсины и наоборот

Бонус: результаты эксперимента по удалению текстур
Используя только дискриминатор всего изображения сразу («Ours-D»), сети внимания начинают изменять помимо «приоритетного» объекта также и его фон, как показано в нижнем ряду:

Оригинал – Muneeb Ul Hassan