Этот туториал для тех, кто знаком с основами JavaScript и основами глубокого обучения для задач NLP (RNN, Attention). Если вы плохо разбираетесь в RNN, я рекомендую вам прочитать «Необоснованную эффективность рекуррентных нейронных сетей» Андрея Карпати.
Перевод статьи «NLP Keras model in browser with TensorFlow.js», автор — Mikhail Salnikov, ссылка на оригинал — в подвале статьи.
В этой статье я попытаюсь охватить три вещи:
- Как написать простую Named-entity recognition (NER) модель — типичная задача NLP.
- Как экспортировать эту модель в формат TensorFlow.js.
- Как сделать простое веб-приложение для поиска именованных объектов в строке без серверной части.
TensorFlow.js — это библиотека JavaScript для разработки и обучения ML-моделей на JavaScript, а также для развертывания в браузере или на Node.js.
В этом примере мы будем использовать простую модель Keras для решения классической задачи NER. Мы будем тренироваться на датасете CoNLL2003 . Наша модель — это просто векторное представление слов, GRU и очень простой механизм внимания. После мы визуализируем вектор внимания в браузере. Если вы знакомы с современными подходами для решения аналогичной задачи, вы знаете, что этот подход не является state-of-the-art подходом. Однако для запуска его в браузере этого вполне достаточно.
Задача и данные
В зависимости от вашего опыта, вы могли слышать об этом под разными названиями — тегирование последовательностей (sequence tagging), Part-of-Speech тегирование или, как в нашей задаче, распознавание именованных объектов (Named-entity recognition).
Обычно задача NER — это задача seq2seq. Для каждого x_i мы должны предсказать y_i, где x — входная последовательность, а y — последовательность именованных объектов.
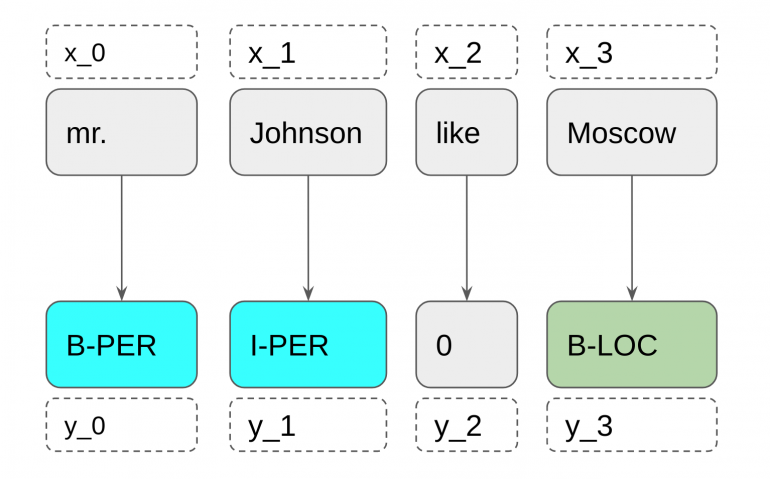
В этом примере мы будем искать людей (B-PER, I-PER), местоположения (B-LOC, I-LOC) и организации (B-ORG, I-ORG). Кроме того, в модели будут определены специальные сущности, MISC — именованные сущности, которые не являются личностями, местами или организациями.
Для начала, нам нужно подготовить данные для компьютера (да, мы будем использовать компьютер для решения этой задачи :)).
В этом туториале мы не ставим перед собой цель получить результат SOTA для набора данных CoNLL2003, поэтому качество нашей предобработки данных будет не на самом высоком уровне. В качестве примера, мы будем загружать данные методом load_data:
def word_preprocessor(word):
word = re.sub(r'd+', '1', re.sub(r"[-|.|,|?|!]+", '', word))
word = word.lower()
if word != '':
return word
else:
return '.'
def load_data(path, word_preprocessor=word_preprocessor):
tags = []
words = []
data = {'words': [], 'tags': []}
with open(path) as f:
for line in f.readlines()[2:]:
if line != 'n':
parts = line.replace('n', '').split(' ')
words.append(word_preprocessor(parts[0]))
tags.append(parts[-1])
else:
data['words'].append(words)
data['tags'].append(tags)
words, tags = [], []
return data
Как вы знаете, нейронные сети не могут работать со словами, только с числами. Вот почему мы должны представлять слова в виде чисел. Это не сложная задача, мы можем перечислить все уникальные слова и записать номер каждого слова вместо него самого. Для хранения цифр и слов мы можем составить словарь. Этот словарь должен поддерживать слова «неизвестный» (UNK) для ситуации, когда мы будем делать прогноз для новой строки со словами, которых нет в словаре. Также словарь должен содержать слово «дополнено» (PAD). Для нейронной сети все строки должны иметь одинаковый размер, поэтому, когда одна строка будет меньше другой, мы заполним пробелы этим словом.
def make_vocab(sentences, tags=False):
vocab = {"(PAD)": PAD_ID, "(UNK)": UNK_ID}
idd = max([PAD_ID, UNK_ID]) + 1
for sen in sentences:
for word in sen:
if word not in vocab:
vocab[word] = idd
idd += 1
return vocab
Далее, давайте напишем простой помощник для перевода предложений в последовательность чисел.
def make_sequences(list_of_words, vocab, word_preprocessor=None):
sequences = []
for words in list_of_words:
seq = []
for word in words:
if word_preprocessor:
word = word_preprocessor(word)
seq.append(vocab.get(word, UNK_ID))
sequences.append(seq)
return sequences
Как вы можете увидеть выше, мы должны дополнить последовательности для работы с нейронной сетью, для этого вы можете использовать внутренний метод Keras — pad sequence.
train_X = pad_sequences(train_data['words_sequences'],
maxlen=MAX_SEQUENCE_LENGTH,
value=PAD_ID, padding='post',
truncating='post')
valid_X = pad_sequences(valid_data['words_sequences'],
maxlen=MAX_SEQUENCE_LENGTH,
value=PAD_ID,
padding='post',
truncating='post')
train_y = pad_sequences(train_data['tags_sequences'],
maxlen=MAX_SEQUENCE_LENGTH,
value=PAD_ID,
padding='post',
truncating='post')
valid_y = pad_sequences(valid_data['tags_sequences'],
maxlen=MAX_SEQUENCE_LENGTH,
value=PAD_ID,
padding='post',
truncating='post')
Модель
Дай угадаю.. RNN?
Верно, она самая. Если точнее, это GRU с простым слоем внимания. Для представления слов используется GloVe. В этом посте я не буду вдаваться в подробности, а просто оставлю здесь код модели. Я надеюсь, что это легко понять.
from tensorflow.keras.layers import (GRU, Dense, Dropout, Embedding, Flatten,
Input, Multiply, Permute, RepeatVector,
Softmax)
from tensorflow.keras.models import Model
from utils import MAX_SEQUENCE_LENGTH
def make_ner_model(embedding_tensor, words_vocab_size, tags_vocab_size,
num_hidden_units=128, attention_units=64):
EMBEDDING_DIM = embedding_tensor.shape[1]
words_input = Input(dtype='int32', shape=[MAX_SEQUENCE_LENGTH])
x = Embedding(words_vocab_size + 1,
EMBEDDING_DIM,
weights=[embedding_tensor],
input_length=MAX_SEQUENCE_LENGTH,
trainable=False)(words_input)
outputs = GRU(num_hidden_units,
return_sequences=True,
dropout=0.5,
name='RNN_Layer')(x)
# Simple attention
hidden_layer = Dense(attention_units, activation='tanh')(outputs)
hidden_layer = Dropout(0.25)(hidden_layer)
hidden_layer = Dense(1, activation=None)(hidden_layer)
hidden_layer = Flatten()(hidden_layer)
attention_vector = Softmax(name='attention_vector')(hidden_layer)
attention = RepeatVector(num_hidden_units)(attention_vector)
attention = Permute([2, 1])(attention)
encoding = Multiply()([outputs, attention])
encoding = Dropout(0.25)(encoding)
ft1 = Dense(num_hidden_units)(encoding)
ft1 = Dropout(0.25)(ft1)
ft2 = Dense(tags_vocab_size)(ft1)
out = Softmax(name='Final_Sofmax')(ft2)
model = Model(inputs=words_input, outputs=out)
return model
После построения модели, мы должны скомпилировать, обучить и сохранить ее. Вы можете догадаться, что для запуска этой модели в браузере мы должны сохранять не только веса для нее, но также описание модели и словари для слов и тегов. Давайте определим метод для экспорта модели и словарей в формат, поддерживаемый JavaScript (в основном JSON):
import json
import os
import tensorflowjs as tfjs
def export_model(model, words_vocab, tags_vocab, site_path):
tfjs.converters.save_keras_model(
model,
os.path.join(site_path, './tfjs_models/ner/')
)
with open(os.path.join(site_path, "./vocabs.js"), 'w') as f:
f.write('const words_vocab = {n')
for l in json.dumps(words_vocab)[1:-1].split(","):
f.write("t"+l+',n')
f.write('};n')
f.write('const tags_vocab = {n')
for l in json.dumps(tags_vocab)[1:-1].split(","):
f.write("t"+l+',n')
f.write('};')
print('model exported to ', site_path)
Наконец, давайте скомпилируем, обучим и экспортируем модель:
model.compile(
loss='categorical_crossentropy',
optimizer='Adam',
metrics=['categorical_accuracy']
)
model.fit(train_X, train_y,
epochs=args.epoches,
batch_size=args.batch_size,
validation_data=(valid_X, valid_y))
export_model(model, words_vocab, tags_vocab, args.site_path)
Полный код для этих шагов вы можете найти в моем репозитории на GitHub в train.py.
Разработка веб-приложения
Итак, модель готова, и теперь мы должны начать разработку веб-приложения для проверки нашей модели режима в браузере. Нам нужно настроить рабочую среду. В принципе, не важно, как вы будете хранить свою модель, веса и словарь, но в качестве примера я покажу вам мое простое решение — локальный сервер node.js.
Нам потребуется два файла: package.json и server.js.
Package.json:
{
"name": "tfjs_ner",
"version": "1.0.0",
"dependencies": {
"express": "latest"
}
}
Server.js:
let express = require("express")
let app = express();
app.use(function(req, res, next) {
console.log(`${new Date()} - ${req.method} request for ${req.url}`);
next();
});
app.use(express.static("./static"));
app.listen(8081, function() {
console.log("Serving static on http://localhost:8081");
});
В server.js мы определили статическую папку для хранения модели, js-скриптов и всех других файлов. Для использования этого сервера, вы должны ввести
npm install && node server.js
в вашем терминале. После этого вы можете получить доступ к своим файлам в браузере по адресу http://localhost:8081.
Далее перейдем к основной части веб-приложения. Существуют index.html, Forex.js и файлы, которые были созданы на предыдущем шаге. Как видите, это очень маленькое веб-приложение. index.html содержит требования и поле для ввода строк пользователем.
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
<main role="main">
<form class="form" onkeypress="return event.keyCode != 13;">
<input type="text" id='input_text'>
<button type="button" id="get_ner_button">Search Entities</button>
</form>
<div class="results">
</div>
</main>
<script src="https://code.jquery.com/jquery-3.3.1.slim.min.js" integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo" crossorigin="anonymous"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
<script src="vocabs.js"></script>
<script src="predict.js"></script>
</body>
</html>
Теперь самая интересная часть туториала — про TensorFlow.js. Вы можете загрузить модель с помощью метода tf.loadLayersModel с использованием оператора await. Это важно, потому что мы не хотим блокировать наше веб-приложение при загрузке модели. Если мы загрузим модель, то у нас будет модель, которая может предсказывать только токены, но как насчет вектора внимания? Для получения данных из внутренних слоев в TensorFlow.js мы должны создать новую модель, в которой выходные слои будут содержать выходные данные и другие слои из исходной модели, например:
let model, emodel;
(async function() {
model = await tf.loadLayersModel('http://localhost:8081/tfjs_models/ner/model.json');
let outputs_ = [model.output, model.getLayer("attention_vector").output];
emodel = tf.model({inputs: model.input, outputs: outputs_});
})();
Здесь model — это оригинальная модель, emodel — модель с attention_vector на выходе.
Предобработка
Теперь мы должны реализовать предварительную обработку строк, как мы это делали в нашем скрипте Python. Для нас это не сложная задача, потому что регулярные выражения в Python и JavaScript очень похожи, как и многие другие методы.
const MAX_SEQUENCE_LENGTH = 113;
function word_preprocessor(word) {
word = word.replace(/[-|.|,|?|!]+/g, '');
word = word.replace(/d+/g, '1');
word = word.toLowerCase();
if (word != '') {
return word;
} else {
return '.'
}
};
function make_sequences(words_array) {
let sequence = Array();
words_array.slice(0, MAX_SEQUENCE_LENGTH).forEach(function(word) {
word = word_preprocessor(word);
let id = words_vocab[word];
if (id == undefined) {
sequence.push(words_vocab['']);
} else {
sequence.push(id);
}
});
// pad sequence
if (sequence.length < MAX_SEQUENCE_LENGTH) {
let pad_array = Array(MAX_SEQUENCE_LENGTH - sequence.length);
pad_array.fill(words_vocab['']);
sequence = sequence.concat(pad_array);
}
return sequence;
};
Предсказания
Теперь мы должны обеспечить передачу данных из простого текстового формата строки в формат TF — тензор. В предыдущем разделе мы написали помощника для перевода строки в последовательность чисел. Теперь мы должны создать tf.tensor из этого массива. Как вы помните, входной слой модели имеет форму (None, 113) , поэтому мы должны расширить размер входного тензора. Ну вот и все, теперь мы можем делать предсказание в браузере методом .predict. После этого вам нужно вывести прогнозируемые данные в браузере, и ваше веб-приложение с нейронной сетью без серверной части готово.
const getKey = (obj,val) => Object.keys(obj).find(key => obj[key] === val); // For getting tags by tagid
$("#get_ner_button").click(async function() {
$(".results").html("word - tag - attention</br><hr>");
let words = $('#input_text').val().split(' ');
let sequence = make_sequences(words);
let tensor = tf.tensor1d(sequence, dtype='int32').expandDims(0);
let [predictions, attention_probs] = await emodel.predict(tensor);
attention_probs = await attention_probs.data();
predictions = await predictions.argMax(-1).data();
let predictions_tags = Array();
predictions.forEach(function(tagid) {
predictions_tags.push(getKey(tags_vocab, tagid));
});
words.forEach(function(word, index) {
$(".results").append(word+' - '+predictions_tags[index]+' - '+attention_probs[index]+'');
});
});
Итог
TensorFlow.js — это библиотека для использования нейронных сетей в браузерах, таких как Chrome, Firefox или Safari. Если вы откроете это веб-приложение на смартфоне iPhone или Android, оно тоже будет работать.
Вы можете найти код этого приложения с некоторыми дополнениями на моем GitHub.