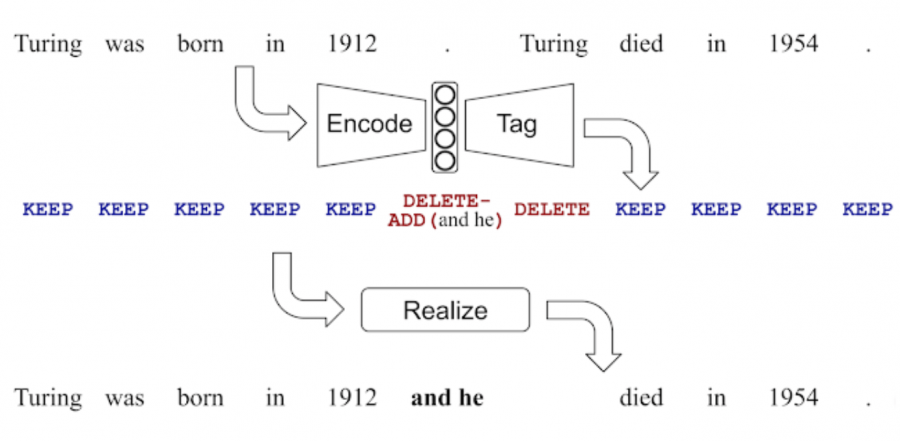
LaserTagger — это нейросетевая модель для генерации текста, которая размечает входную последовательность. Нейросеть рассматривает задачу генерации текста как задачу редактирования текста. Целевые тексты восстанавливаются из входных текстов с помощью трех операций редактирования: оставить токен, удалить токен и добавить фразу до токена. LaserTagger предсказывает, какие операции необходимо провести на входном тексте, чтобы восстановить целевую последовательность.
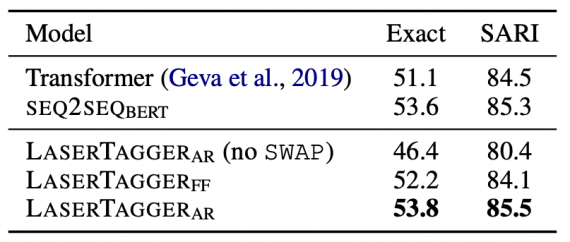
Модель комбинирует в себе энкодер из BERT с авторегрессионным декодером из архитектуры трансформера. Исследователи оценили нейросеть на четырех задачах: объединение предложений (sentence fusion), разбиение на предложения (sentence splitting), абстрактивная суммаризация и корректирование грамматики. LaserTagger обошел state-of-the-art модели на трех из четырех задачах. Нейросеть в особенности подходит для случаев, когда данные для обучения ограничены в размере. Кроме того, на инференсе модель в два раза быстрее, чем сравнимые seq2seq подходы.
Описание проблемы
Sequence-to-sequence (seq2seq) модели популярны для задач машинного перевода и генерации текста. Несмотря на это, у текущих моделей есть ряд ограничений, которые варьируются в зависимости от задачи:
- Генерация последовательностей, которые не связаны с входным текстом (галлюцинации);
- Необходимость в обучающих выборках большого размера, чтобы модель генерировала связный текст;
- Низкая скорость моделей на инференсе, что связано с тем, что они генерируют последовательность токен за токеном
LaserTagger справляется с последним ограничением так, что итоговая последовательность генерируется на основе операций с входной последовательностью. Такой подход позволяет сократить время, которое модель тратит на выдачу целевой последовательности.
Читайте также: Топ 5 нейросетей для генерации текста на русском языке
Что внутри LaserTagger
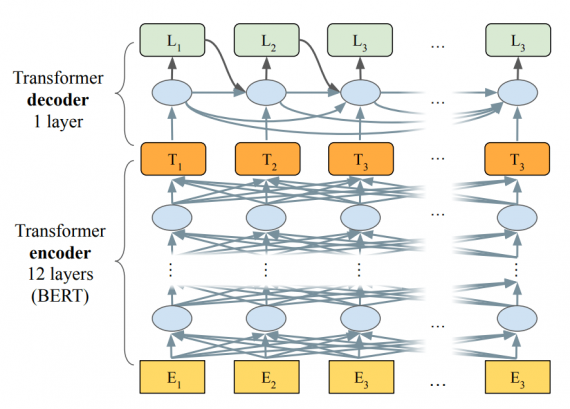
Отличительной характеристикой большинства задач генерации текста является схожесть входной и целевой последовательностей. LaserTagger использует эту характеристику в своей архитектуре. Энкодер модели заимствовали у BERT. Он состоит из 12 слоев. Декодер модели, в свою очередь, взяли из Transformer архитектуры.
Тестирование работы модели
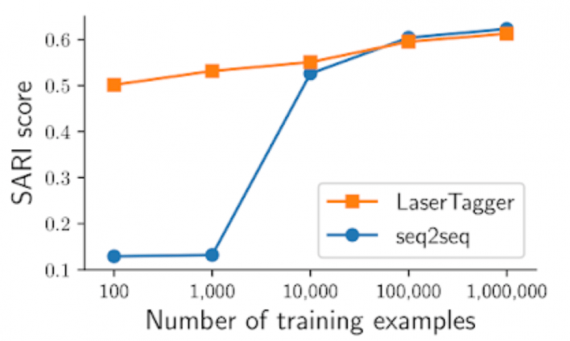
Исследователи сравнили LaserTagger с seq2seq моделью, основанной на BERT, и с Transformer. Для случаев, когда количество обучающих данных ограничено, LaserTagger обходит seq2seq модель.