
Synesthetic Variational Autoencoder (SynVAE) — это нейросеть, которая на основе изображения генерирует музыку. Модель обучалась unsupervised.
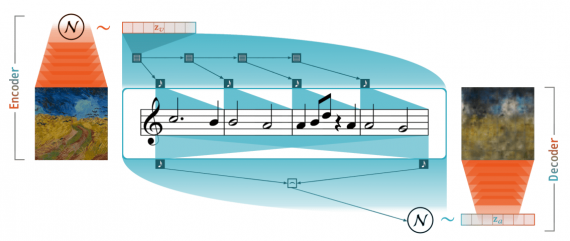
SynVAE состоит из объединенных визуального VAE и MusicVAE. Изображение кодируется в музыку, а затем реконструируется на основе сгенерированной аудиозаписи. Модель обучается так, чтобы минимизировать разницу между восстановленным изображением и входным изображением.
Как это работает
Сначала изображение кодируется в вектор zv с помощью VisVAE кодировщика. Затем вектор изображения поступает на вход MusicVAE декодировщика. На выходе MusicVAE выдает сгенерированную аудиозапись. Во время обучения музыка последовательно перекодируется в вектор za с помощью MusicVAE кодировщика. Затем перекодированная аудиозапись поступает на вход VisVAE декодировщика, чтобы восстановить входное изображение.
Примеры использования
MNIST
На базовом датасете с изображениями цифр модель генерировала схожие аудиозаписи для изображений одинаковой цифры. Исследователи опросили добровольцев, могут ли они различить «0», «1» и «4» по сгенерированным аудиозаписям. В 73% случаев опрашиваемые верно сопоставляли аудиозапись с изображенной цифрой.
Из картины в музыку
Датасет Behance Artistic Media dataset (BAM) содержит ∼2.3 миллиона размеченных работ современного искусства. В основном данные состоят из картин, написанных акварелью или маслом. Модель кодировала в музыку высокоуровневую информацию о картинах: цвета или общая структура. По результатам опроса, в 71% случаев люди верно сопоставляли сгенерированную аудиозапись и картину.






