Пора переходить к работе с реальными данными! Мы будем работать с дорожными знаками Бельгии. Дорожный трафик — понятная тема, но не помешает уточнить, какие данные включены в датасет, перед тем как приступить к программированию.
Перед прочтением статьи рекомендуем изучить:
- TensorFlow туториал. Часть 1: тензоры и векторы
- TensorFlow туториал. Часть 2: установка и начальная настройка
В этом разделе вы получите всю необходимую для продолжения изучения туториала информацию:
- Текст на дорожных знаках в Бельгии обычно приведен на голландском и французском языках. Это полезно знать, но для датасета, с которым вы будете работать, это не слишком важно!
- В Бельгии шесть категорий дорожных знаков: предупреждающие знаки, знаки приоритета, запрещающие знаки, предписывающие знаки, знаки, связанные с парковкой и стоянкой у дорог, и, наконец, обозначения.
- 1 января 2017 года с бельгийских дорог было снято более 30 000 дорожных знаков. Это были запрещающие знаки, ограничивающие максимальную скорость вождения.
- Снятие знаков связано с длительной дискуссией в Бельгии (и во всем Европейском Союзе) о чрезмерном количестве дорожных знаков.
Загрузка датасета
Теперь, когда вы знакомы со спецификой бельгийского трафика, пришло время скачать датасет. Вы должны скачать два zip-файла в разделе «BelgiumTS for Classification (cropped images)» с названиями «BelgiumTSC_Training» и «BelgiumTSC_Testing».
Совет. Если вы скачали файлы или сделаете это после прочтения туториала, взгляните на структуру папок, которые вы загрузили! Вы увидите, что папки тестирования и обучения содержат 61 подпапку, соответствующую 61 типам дорожных знаков, которые вы будете использовать для классификации в этом туториале. Кроме того, вы обнаружите, что файлы имеют расширение .ppm или Portable Pixmap Format. Вы скачали изображения дорожных знаков!
Давайте начнем с импорта данных в рабочую область. Начнем со строк кода, которые отображаются под пользовательской функцией load_data():
- Сначала установите ROOT_PATH. Этот путь к каталогу, в котором находятся данные для обучения и тестирования.
- Затем добавьте пути к вашему ROOT_PATH с помощью функции join(). Сохраните эту пути в train_data_directory и test_data_directory.
- Вы увидите, что после этого можно вызвать функцию load_data() и передать в нее train_data_directory.
- Теперь сама функция load_data() запускается путем сбора всех подкаталогов, присутствующих в train_data_directory; она делает это с помощью спискового включения, что является естественным способом составления списков — то есть, если вы найдете что-то в train_data_directory, вы проверяете, папка ли это и, если так и есть, добавляете ее в свой список. Помните, что каждый подкаталог представляет собой метку.
- Затем вам нужно перебрать подкаталоги. Сначала вы инициализируете два списка, labels и images. Затем вы собираете пути подкаталогов и имена файлов изображений, которые хранятся в этих подкаталогах. После этого можно собрать данные в двух списках с помощью функции append().
def load_data(data_directory):
directories = [d for d in os.listdir(data_directory)
if os.path.isdir(os.path.join(data_directory, d))]
labels = []
images = []
for d in directories:
label_directory = os.path.join(data_directory, d)
file_names = [os.path.join(label_directory, f)
for f in os.listdir(label_directory)
if f.endswith(".ppm")]
for f in file_names:
images.append(skimage.data.imread(f))
labels.append(int(d))
return images, labels
ROOT_PATH = "/your/root/path"
train_data_directory = os.path.join(ROOT_PATH, "TrafficSigns/Training")
test_data_directory = os.path.join(ROOT_PATH, "TrafficSigns/Testing")
images, labels = load_data(train_data_directory)
Обратите внимание, что в приведенном выше блоке данные для обучения и тестирования находятся в папках с названиями «training» и «testing», которые являются подкаталогами другого каталога «TrafficSigns». На компьютере это может выглядеть примерно так: «/Users /Name /Downloads /TrafficSigns», а затем две подпапки под названием «training» и «testing».
Исследование данных
Когда данные загружены, пришло время для их исследования! Для начала можно провести элементарный анализ с помощью атрибутов ndim и size массива images:
Обратите внимание, что переменные images и labels являются списками, поэтому вам, возможно, придется воспользоваться np.array() для преобразования переменных в массив в рабочей области. Но здесь это уже сделано для вас!
# Вывести размерность 'images' print(images.ndim) # Вывести количество элементов в 'images' print(images.size) # Вывести первое значение 'images' images[0]
Обратите внимание, что значение images[0], которое вы вывели, на самом деле представляют собой одно изображение, представленное массивами в массиве! Это может показаться нелогичным, но вы привыкните к этому, когда будете работать с изображениями в проектах машинного или глубокого обучения.
Далее, обратимся к labels, но на этот раз никаких сюрпризов не будет:
# Вывести размерность 'labels' print(labels.ndim) # Вывести число элементов в 'labels' print(labels.size) # Вывести длину массива 'labels' print(len(set(labels)))
Эти цифры дают вам представление о том, корректно ли произведен импорт, и каков размер ваших данных. На первый взгляд все работает так, как вы ожидали, и видно, что размер массива значителен, если учесть, что вы имеете дело с массивами внутри массивов.
Совет. Попробуйте добавить в свои массивы следующие атрибуты, чтобы получить дополнительную информацию о распределении памяти: длину одного элемента массива в байтах и общее количество байтов, занимаемых элементами массива: flags, itemsize и nbytes.
Затем можно изучить распределение дорожных знаков по типам:
# Импортировать модуль 'pyplot' import matplotlib.pyplot as plt # Построить гистограмму с 64 точками - значениями 'labels' plt.hist(labels, 62) # Вывести график plt.show()
Отлично! Давайте посмотрим на полученную гистограмму:
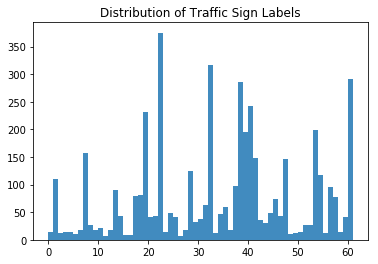
Хорошо видно, что не все типы дорожных знаков одинаково представлены в датасете. Это то, с чем вы столкнетесь позже, когда будете работать с данными, прежде чем приступать к моделированию нейронной сети. На первый взгляд видно: количество знаков типов 22, 32, 38 и 61 определенно преобладает над остальными. Запомните это, в следующем разделе вам пригодится эта информация.
Визуализация данных
После изучения предыдущего раздела вы уже имеете небольшое представление о данных. Но когда данные — это изображения, их, конечно, нужно визуализировать.
Давайте посмотрим на несколько случайных знаков:
- Во-первых, убедитесь, что вы импортируете модуль pyplot пакета matplotlib под общепринятым названием plt.
- Затем создайте список из 4 случайных чисел. Они будут использоваться для выбора дорожных знаков из массива images, загруженного в прошлом разделе. В нижеследующем примере это будут числа 300, 2250, 3650 и 4000.
- Затем для каждого элемента этого списка, от 0 до 4, вы создаете графики без осей (чтобы они не мешали сосредоточиться на изображениях). На этих графиках вы увидите конкретные изображения из массива images, которые соответствует номеру индекса i. На первом шаге цикла вы получите i = 300, во втором — 2250 и так далее. Наконец, нужно расположить графики так, чтобы между ними было достаточно пространства.
- Последнее — выведите ваши графики с помощью функции show()!
Код:
# Import the `pyplot` module of `matplotlib`
import matplotlib.pyplot as plt
# Determine the (random) indexes of the images that you want to see
traffic_signs = [300, 2250, 3650, 4000]
# Fill out the subplots with the random images that you defined
for i in range(len(traffic_signs)):
plt.subplot(1, 4, i+1)
plt.axis('off')
plt.imshow(images[traffic_signs[i]])
plt.subplots_adjust(wspace=0.5)
plt.show()
Как можно догадаться, знаки каждого из 62 типов отличаются друг от друга.
Но что еще можно заметить? Взглянем на изображения ниже:

Эти четыре изображения имеют разный размер!
Конечно, вы могли бы поиграться с числами в списке traffic_signs и более подробно изучить этот вопрос, но, как бы то ни было, это важный нюанс, который придется учитывать, когда вы начнете работать с данными для подачи в нейронную сеть.
Давайте подтвердим гипотезу о разных размерах, выводя разрешения снимков, то есть минимальные и максимальные значения каждого выведенного изображения.
Код ниже сильно похож на тот, который использовался для создания графика, но отличается тем, что сейчас выводится не только изображение, но и его размер:
# Импорт 'matplotlib'
import matplotlib.pyplot as plt
# Задание (случайных) номеров изображений, которые вы хотите вывести
traffic_signs = [300, 2250, 3650, 4000]
# Заполнение графиков изображениями и вывод размеров
for i in range(len(traffic_signs)):
plt.subplot(1, 4, i+1)
plt.axis('off')
plt.imshow(images[traffic_signs[i]])
plt.subplots_adjust(wspace=0.5)
plt.show()
print("shape: {0}, min: {1}, max: {2}".format(images[traffic_signs[i]].shape,
images[traffic_signs[i]].min(),
images[traffic_signs[i]].max()))
Обратите внимание на то, как вы используется метод format() в строке «shape: {0}, min: {1}, max: {2}», чтобы заполнить аргументы {0}, {1} и {2}.

Теперь, когда вы увидели сами изображения, можно вернуться к гистограмме, которая была построена на первых этапах изучения датасета; вы можете легко сделать это, выводя по одному изображению из каждого типа знаков:
# Импорт модуля 'pyplot' 'matplotlib'
import matplotlib.pyplot as plt
# Задание типов
unique_labels = set(labels)
# Инициализация графика
plt.figure(figsize=(15, 15))
# Задание счетчика
i = 1
# Для каждого типа:
for label in unique_labels:
# Выбирается первое изображение каждого типа:
image = images[labels.index(label)]
# Задание 64 графиков
plt.subplot(8, 8, i)
# Выключение осей
plt.axis('off')
# Добавление заголовка каждому графику
plt.title("Label {0} ({1})".format(label, labels.count(label)))
# Увеличить значение счетчика на 1
i += 1
# Вывод первого изображения
plt.imshow(image)
# Вывод всего графика
plt.show()
Обратите внимание, что даже если вы определяете 64 графика, не на всех из них будут изображения (так как есть всего 62 типа знаков!). Обратите также внимание на то, что опять же, вы не выводите оси, чтобы не отвлекаться на них.

Как было видно из гистограммы, количество фотографий знаков с типами 22, 32, 38 и 61 значительно больше остальных. Эта видно из из графика выше: есть 375 снимков с меткой 22, 316 снимков с меткой 32, 285 снимков с меткой 38 и, наконец, 282 снимка с меткой 61.
Один из самых интересных вопросов, который можно задать сейчас: есть ли связь между всеми этими знаками — может быть, они все являются обозначающими?
Давайте рассмотрим более подробно: видно, что метки 22 и 32 являются запретительными знаками, но метки 38 и 61 являются указательными знаками и знаками приоритета, соответственно. Это означает, что между этими четырьмя знаками нет непосредственной связи, за исключением того факта, что половина знаков, наиболее широко представленных в датасетах, являются запрещающими.
Извлечение признаков
Теперь, когда вы тщательно изучили свои данные, пришло время засучить рукава! Давайте кратко отметим, что вы обнаружили, чтобы убедиться, что вы не забыли какие-либо моменты:
- Изображения имеют разный размер;
- Есть 62 метки (помним, что нумерация меток начинаются с 0 и заканчиваются на 61);
- Распределение типов знаков трафика довольно неравномерно; между знаками, которые в большом количестве присутствовали в наборе данных, нет никакой связи.
Теперь, когда у вас есть четкое представление о том, с чем нужно разобраться, можно подготовить данные к подаче в нейронную сеть или любую модель, в которую вы хотите их подавать. Начнем с извлечения признаков — нужно сделать одинаковый размер изображений и перевести их в черно-белую гамму. Преобразовать изображения в оттенки серого нужно потому, что цвет имеет меньшее значение при классификации. Однако для распознавания знаков цвет играет большую роль! Поэтому в этих случаях преобразование делать не нужно!
Масштабирование изображений
Чтобы сделать размеры изображений одинаковыми, можно воспользоваться функцией skimage или библиотекой Scikit-Image, которая представляет собой набор алгоритмов для обработки изображений.
Во втором случае случае будет полезен модуль transform, так как в нем есть функция resize(); она снова использует списковое включение, чтобы сделать разрешение снимков равным 28×28 пикселей. Повторюсь: вы увидите, что фактически составляете список — для каждого изображения в массиве image вы выполните операцию преобразования, которую позаимствуете из библиотеки skimage. Наконец, вы сохраняете результат в переменной images28:
# Импорт модуля 'transform' из 'skimage' import transform # Масштабирование изображений в 'image' array images28 = [transform.resize(image, (28, 28)) for image in images]
Выглядит очень просто, не так ли?
Обратите внимание, что изображения теперь четырехмерны: если вы конвертируете images28 в массив и привязываете атрибут shape, видно, что размеры imeges28 равны (4575, 28, 28, 3). Изображения 784-мерные (потому что ваши изображения имеют размер 28 на 28 пикселей).
Вы можете проверить результат операции масштабирования путем повторного использования кода, который вы использовали выше, для построения 4 случайных изображений с помощью переменной traffic_signs; просто не забудьте изменить images на images28.
Результат:

Обратите внимание, что, поскольку вы изменили масштаб, значения min и max также изменились; сейчас они все лежат в одном диапазоне, что действительно здорово, потому что теперь вам не нужно производить нормировку данных!
Преобразование изображений в оттенки серого
Как сказано во введении к этому разделу, цвет на фотографиях имеет меньшее значение, когда вы занимаетесь классификацией. Вот почему вы также столкнетесь с проблемой преобразования изображений в оттенки серого.
Обратите внимание, что вы также можете самостоятельно проверить, что произойдет с конечными результатами работы вашей модели, если вы не выполните этот конкретный шаг.
Как и при масштабировании, вы можете использовать библиотеку Scikit-Image; в этом случае вам понадобится модуль color с функцией rgb2gray().
Это будет просто!
Однако не забудьте преобразовать переменную images28 в массив, так как функция rgb2gray() в качестве аргумента принимает именно массивы.
# Импорт `rgb2gray` из`skimage.color` from skimage.color import rgb2gray # Конвертация `images28` в массив images28 = np.array(images28) # Конвертация `images28` в оттенки серого images28 = rgb2gray(images28)
Проверьте результат вашего преобразования в оттенки серого, выведя некоторые из изображений; для этого используйся несколько модифицированный код:
import matplotlib.pyplot as plt
traffic_signs = [300, 2250, 3650, 4000]
for i in range(len(traffic_signs)):
plt.subplot(1, 4, i+1)
plt.axis('off')
plt.imshow(images28[traffic_signs[i]], cmap="gray") plt.subplots_adjust(wspace=0.5)
# Вывод графика
plt.show()
Обратите внимание, что вам обязательно нужно указать цветовую карту или cmap и выставить значение ‘gray’ для вывода изображений в оттенках серого. Это связано с тем, что imshow() по умолчанию использует тепловую цветовую карту.
Совет. Поскольку этот блок используется в туториале несколько раз, будет полезно подумать, как можно сделать его функцией 🙂
Эти два шага являются очень простыми; другие операции, которые вы можете применить к снимкам (поворот, размытие, смещение, изменение яркости), приводят к разрастанию данных. Если хотите, можно также автоматизировать выполнение всей последовательности действий, которую вы производите со своими изображениями.
В следующей части — глубокое обучение c TensorFlow.
Интересные статьи:
- Google выпустили дополнения к Tensorflow Object Detection API
- Прогнозирование фондового рынка на Python с помощью Stocker
- Word2Vec: как работать с векторными представлениями слов