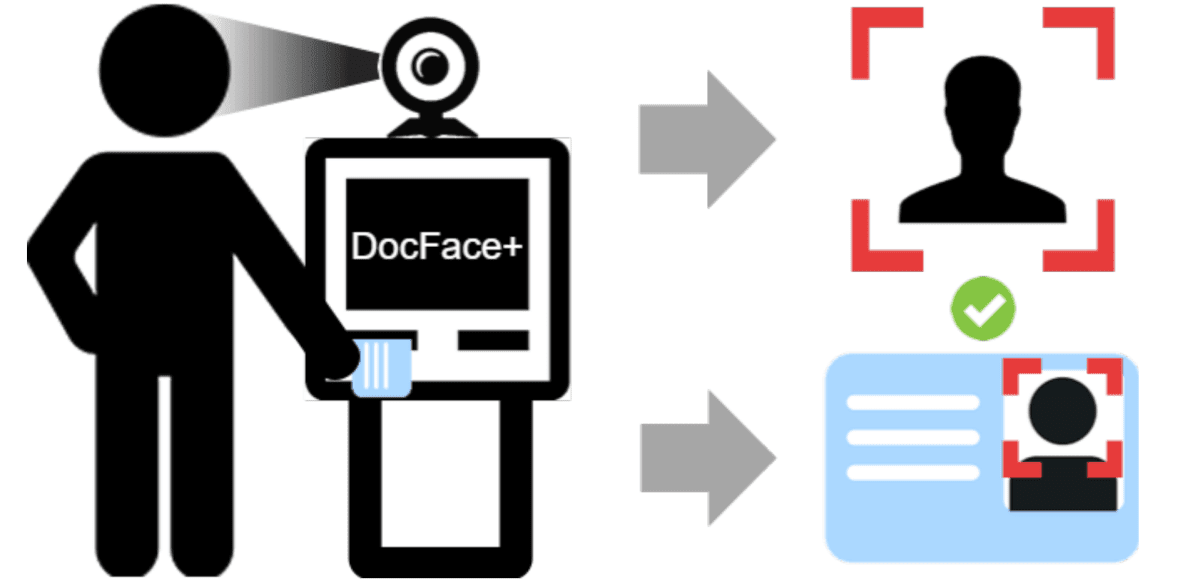
Подтверждение личности — механизм обеспечения безопасности, широко применяющийся в контроле доступа при пересечении международных границ и управлении банковскими транзакциями. Кроме того, подтверждение личности требуется практически каждый день: при входе в офис, при работе с государственными организациями, при оформлении документов. Часто процесс выполняется вручную, и потому он медленен и требует наличия сотрудников-операторов.

Автоматизированная система подтверждения личности ускорит этот верификацию и обеспечит полную безопасность действий, требующих подтверждения личности. Один из самых простых способов сделать это — создать алгоритм (и интерфейс), который будет сопоставлять пары документ-селфи.
Современные исследования
Ранее были предприняты как успешные, так и безуспешные попытки реализовать автоматизированную систему подтверждения личности. Успешным примером является австралийская SmartGate. Это автоматизированная система пограничного контроля с самообслуживанием, управляемая австралийскими пограничными войсками и расположенная на контрольно-пропускных иммиграционных пунктах в залах прибытия восьми австралийских международных аэропортов. В ней используется камера для захвата контрольного изображения и выполняется попытка его сопоставления с фотографией в документах. В Китае такие системы были установлены на вокзалах и в аэропортах.
Несмотря на то, что были предприняты попытки сопоставления пар документ-селфи с использованием традиционных методов компьютерного зрения, более эффективные методы основаны на глубоком обучении. Исследователь Zhu с коллегами предложил первый метод глубокого обучения для сопоставления фотографий с использованием сверточных нейронных сетей.
Новый метод
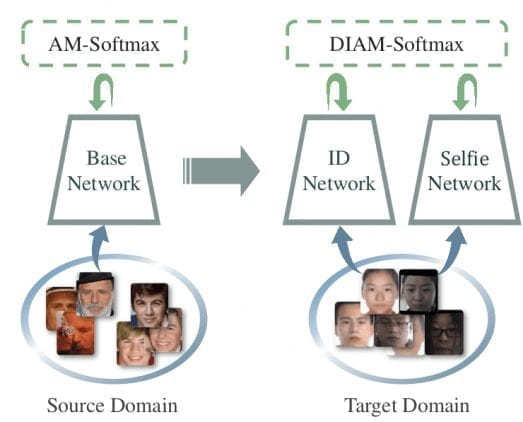
В своей новой статье исследователи из Мичиганского университета предложили улучшенную версию DocFace — метода глубокого обучения для сопоставления документов с селфи.
В работе показано, что методы оптимизации на основе градиентного спуска сходятся медленно, если у большого числа классов мало выборок — как в случае существующих датасетов «документы-селфи». Для решения этой проблемы ученые предложили метод, названный Dynamic Weight Imprinting (DWI). Кроме того, они разработали новую систему распознавания для обучения единым представлениям на основе пар «документ-селфи» и проект с открытым исходным кодом под названием DocFace+ для сопоставления пар «документ-селфи».
Суть метода
Проблемы и ограничения предследуют разработчиков на каждом шагу при создании автоматизированной системы сопоставления пар «документ-селфи». Многие из них нетипичны для традиционных систем распознавания лиц.
Две основными проблемы:
- низкое качество как документов, так и селфи из-за сжатия;
- большой промежуток времени между датой выпуска документа и моментом верификации.
Метод целиком основан на transfer learning. Модель основной нейронной сети обучается на большом датасете (MS-Celeb 1M), а затем свойства переносятся в целевой домен пар «документ-селфи».

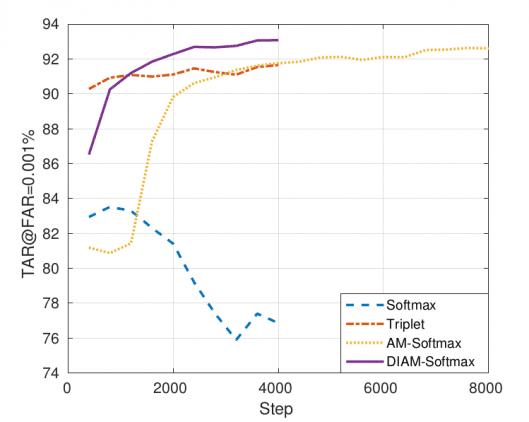
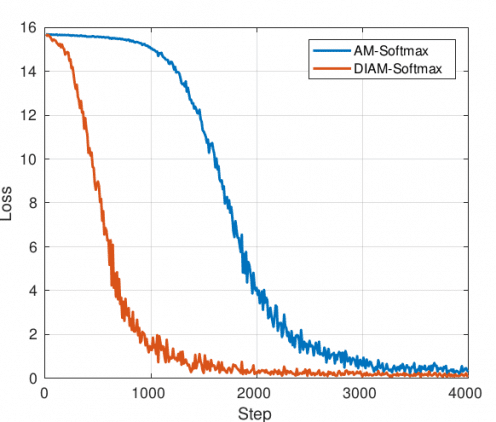
Утверждая, что алгоритм сходится крайне медленно и часто обучение «застревает» в локальных минимумах при работе со многими классами, имеющими малую выборку, исследователи предлагают использовать функцию потерь Additive Margin Softmax (AM-Softmax) наряду с новым методом оптимизации, который они называют DWI.
Dynamic Weight Imprinting
Так как стохастический градиентный спуск обновляет сеть с помощью малых пакетов, в случае двух снимков (например, пары документ-селфи) каждый вектор весовых коэффициентов будет принимать сигнал лишь дважды в течение одной эпохи. Эти редкие сигналы мало влияют на веса классификатора. Для преодоления этой проблемы предложен новый метод оптимизации, идея которого состоит в том, чтобы уточнять весовые коэффициенты на основе выборочных функций и, следовательно, избежать недоопределения весов классификатора и ускорить сходимость.
По сравнению с методом стохастического градиентного спуска и другими методами оптимизации на основе градиентов предлагаемый метод DWI обновляет весовые коэффициенты только на основе истинной выборки. Он обновляет веса только тех классов, которые присутствуют в малых пакетах, и хорошо работает с большими датасетами, в которых набор весовых коэффициентов всех классов слишком велик для загрузки, и для обучения можно использовать лишь часть весовых коэффициентов.
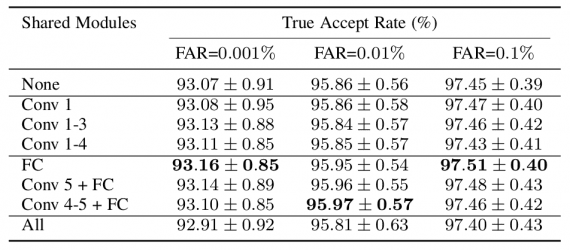
Исследователи обучили популярную архитектуру Face-ResNet с использованием стохастического градиентного спуска и функции потерь AM-Softmax. Затем они точно настроили модель на датасет пар «документ-селфи», связывая предлагаемый метод оптимизации DWI с AM-Softmax. Наконец, на специфических для документов и селфи свойствах была обучена пара одноуровневых сетей, обменивающихся параметрами высокого уровня.
Результаты
DWI демонстрирует превосходные результаты, давая в координатах TAR 97,51 ± 0,40%. Авторы утверждают, что их подход с использованием датасета MS-Celeb-1M и функции потерь AM-Softmax дает 99,67% точности в стандартном протоколе проверки LFW и скорости верификации 99,60% при FAR, равному 0,1% по протоколу BLUFR.

Сравнение с другими подходами
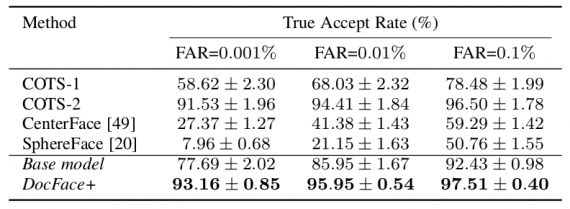
Dynamic Weight Imprinting был сопоставлен с другими методами поиска совпадений лиц, так как на данный момент не существует подходов сопоставления пар «документ-селфи». Сравнение с этими методами проводилось в координатах TAR и FAR и приведено в таблице:

Заключение
Метод DocFace+ для сопоставления пар документ-селфи показывает потенциал transfer learning, особенно в случае недостатка данных. Высокая точность сопоставления пар документ-селфи доказывает, что алгоритм может потенциально использоваться в системах подтверждения личности. Кроме того, представлен новый метод оптимизации DWI с быстрой сходимостью и высокой обобщающей способностью.