
Возможно, наиболее важное событие прошедшего года в NLP — релиз BERT, мультиязычной модели на основе трансформера, которая показала state-of-the-art результаты в нескольких задачах NLP. BERT — двунаправленная модель с transformer-архитектурой, заменившая собой последовательные по природе рекуррентные нейронные сети (LSTM и GRU), с более быстрым подходом на основе механизма внимания. Модель также предобучена на двух задачах без учителя — моделирование языковых масок и предсказание следующего предложения. Это позволяет нам использовать предобученную модель BERT, настраивая её под конкретные задачи, такие как определение эмоциональной окраски текста, вопросно-ответные системы и многие другие.
Перед вами перевод статьи Multi-label Text Classification using BERT – The Mighty Transformer, автор — Каушал Триведи. Ссылка на оригинал — в подвале статьи.
Ретроспектива
Прошедший год стал волнующим для технологий обработки естественного языка (NLP) и ознаменовал переход к повсеместному использованию глубоких нейронных сетей. Исследования в области предобученных моделей привели к большому скачку в state-of-the-art результатах для многих NLP задач: классификация текстов, построение выводов по тексту, вопросно-ответные системы.
Вот некоторые из ключевых вех: ELMo, ULMFiT, OpenAI Transformer и GPT-2. Все эти подходы позволили предобучать языковые модели без учителя на больших корпусах данных, таких как статьи из википедии, и дальше подстраивать эти модели под конкретные задачи.
Задача — классификации текста с несколькими метками
В этой статье мы сфокусируем внимание на применении BERT к задачам текстовой классификации с несколькими метками. Традиционная задача классификации предполагает, что каждый документ принадлежит одному или нескольким классам, то есть меткам. Иногда такую задачу называют задачей классификации с несколькими метками, а в случае с 2 классами — бинарной классификацией.
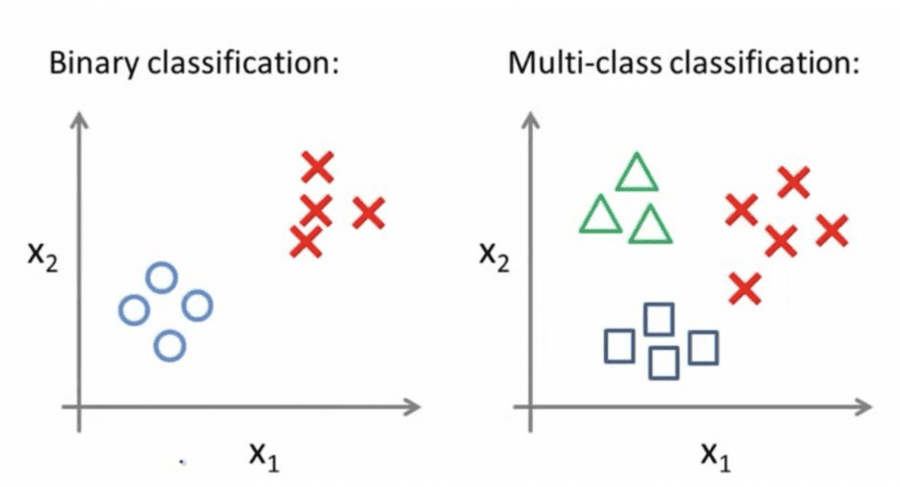
С другой стороны, классификация задач с несколькими метками предполагает, что текст может быть одновременно и независимо причислен к нескольким классам. Такие задачи классификации имеют широкое применение в реальном мире: классификация товаров на предприятии, приписывание нескольких жанров фильмам. В области обслуживания клиентов эта технология может использоваться для определения мотивов электронных писем клиентов.
В качестве бенчмарка модели BERT для классификации текста с несколькими метками будем использовать соревнование на Kaggle Toxic Comment Classification Challenge. В этом соревновании требовалось построить модель, которая будет классифицировать токсичные комментарии по заданному отрывку текста.
Комментарии будем классифицировать на: токсичный, очень токсичный, неприличный, угрожающий, оскорбляющий, личная ненависть. Это будут метки нашей модели.
С чего начать
Google Research недавно выпустил реализацию BERT с открытым кодом на tensorflow и представил следующие предобученные модели:
- BERT-Base, текст приведен к нижнему регистру, удалены маркеры акцента: 12 слоев, 768 узлов , 12 выходов, 110M параметров
- BERT-Large, текст приведен к нижнему регистру, удалены маркеры акцента : 24 слоя, 1024 узлов, 16 выходов, 340M параметров
- BERT-Base, регистр и акцент сохранены: 12 слоев, 768 узлов, 12 выходов , 110M параметров
- BERT-Large, регистр и акцент сохранены: 24 слоев, 1024 узлов, 16 выходов, 340M параметров
- BERT-Base, многоязыковая модель (новая, рекомендуется): 104 языков, 12 слоев, 768 узлов, 12 выходов, 110M параметров
- BERT-Base, Китайский язык: упрощенный и традиционный, 12-слоев, 768 узлов, 12 выходов, 110M параметров
Для нашей задачи будем использовать модель Bert-Base c приведением к нижнему регистру и удалением маркеров акцентов. Эта модель имеет 12 attention-слоев, а весь текст приведен к нижнему регистру при помощи токенайзера. Запускать модель будем на инстансе p3.8xlarge EC2 на облаке AWS; такая конфигурация инстанса эквивалентна четырем GPU Tesla V100 с суммарной памятью в 64 гигабайта на GPU.
Так как я отдаю предпочтение PyTorch перед Tensorflow, будем использовать BERT от HuggingFace, доступный по ссылке. Предварительно мы преобразовали предобученные чекпоинты на Tensorflow в веса PyTorch с помощью скрипта, находящегося в репозитории HuggingFace.
Наша реализация в большой степени основана на примере run_classifier оригинальной реализации BERT.
Представление данных
Данные будут представлены в классе InputExample.
- text_a: комментарии в текстовом виде;
- text_b: не используется;
- Labels (метки): список меток для комментария из тренировочных данных (должен быть пустым для тестовых данных по очевидным причинам).
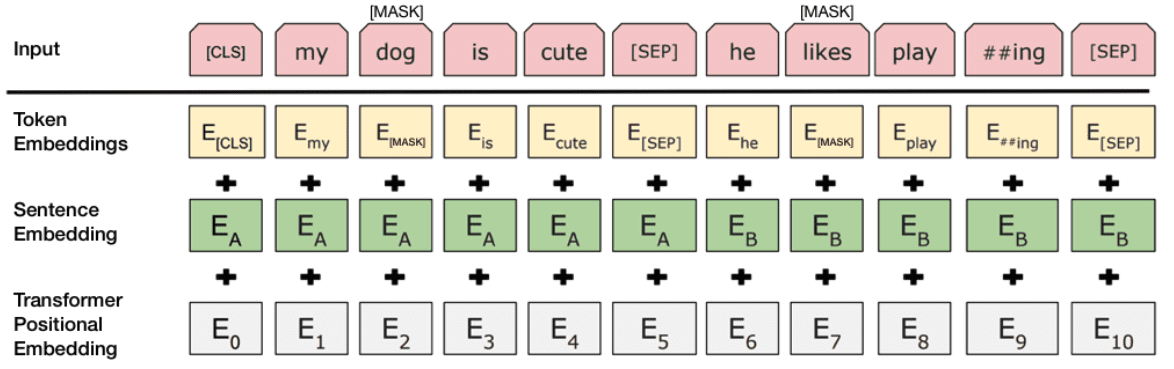
Конвертируем InputExample в признак, который понимает BERT. Признак будет представлен классом InputFeatures.
- input_ids: список id для токенизированного текста;
- input_mask: устанавливается значение 1 для реальных токенов, 0 для токенов заполнения;
- Segment_ids: в нашем случае будет установлено как список из единиц;
- label_ids: one-hot кодированные метки для текста.
Токенизация
Токенизация — разбиение (разделении) длинных строк текста на более мелкие единицы: абзацы на предложения, предложения на слова.
Модель BERT-Base использует словарь из 30522 слов. Процесс токенизации означает разбиение входного текста на список токенов, доступных в словаре. Для того чтобы работать со словами, не представленными в словаре, BERT использует метод на основе WordPiece токенизации, называемый BPE. В таком подходе слово, отсутствующее в словаре, постепенно разбивается на более мелкие части; то есть слово представляется набором из его частей. Так как части слова уже находятся в словаре, узнаем представление контекста для частей, а контекст слова будет комбинацией контекстов частей. Для более детального рассмотрения процесса токенизации можно обратиться к статье Neural Machine Translation of Rare Words with Subword Units.
На мой взгляд, это такой же важный прорыв, как и сам BERT.
Архитектура модели
Будем адаптировать класс BertForSequenceClassification для нашей задачи классификации.
Основное изменение здесь — использование бинарной кросс-энтропийной функции потерь с logit-функцией (BCEWithLogitsLoss) вместо классической кросс-энтропийной функции, используемой для мультиклассовой классификации. Бинарная кросс-энтропийная потеря позволяет нашей модели присваивать меткам независимые вероятности.
Код модели показывает слои модели вместе с их размерами.
- BertEmbeddings: входной слой вложения
- BertEncoder: 12 BERT attention-слоев
- Classifier: наш мультиклассовый классификатор с числом признаков out_features=6, соответствующих 6 меткам.
Обучение
Цикл обучения идентичен оригинальной реализации BERT в run_classifier.py. Обучаем модель на протяжении 4 эпох (epoch) с размером батча 32 и длиной последовательности 512, максимально возможной для предобученных моделей. Параметр learning rate задаем на уровне 3e-5, как рекомендовано в оригинальной статье.
Есть возможность обучать сеть на нескольких GPU, поэтому используем обертку модели Pytorch внутри модуля DataParallel. Это позволит распределить обучение на все доступные графические процессоры.
Мы не будем использовать технику FP16 с половинной точностью, так как по некоторым причинам бинарная кросс-энтропийная функция потерь с логитами не поддерживает обработку FP16. На самом деле это не повлияет на конечный результат, просто для обучения потребуется немного больше времени.
Метрика качества
Мы адаптировали метрическую функцию точности, чтобы включить в неё порог, заданный по умолчанию как 0.5.
Для мультиклассовой задачи намного более важная метрика — кривая ROC-AUC. Она также является метрикой качества в соревновании Kaggle. Рассчитываем ROC-AUC для каждой метки по отдельности. Также будем использовать микроусреднение по результатам ROC-AUC для каждой метки.
Результаты
Мы проводили эксперимент несколько раз с некоторыми изменениями, но получали более или менее похожие результаты, представленные ниже:
- Потери во время тренировки (Training Loss): 0.022
- Потери на валидационном сете (Validation Loss): 0.018
- Точность на валидационном сете (Validation Accuracy): 99.31%
Метрика ROC-AUC для каждого класса комментариев:
- Токсичный (toxic): 0.9988
- Очень токсичный (severe-toxic): 0.9935
- Неприличный (obscene): 0.9988
- Угрожающий (threat): 0.9989
- Оскорбляющий (insult): 0.9975
- Личная ненависть (identity_hate): 0.9988
- Микроусреднение: 0.9987
Кажется, что результаты впечатляющие, и, похоже, мы создали почти идеальную модель для определения токсичности комментариев.
Результаты на Kaggle
Мы запустили нейросеть на датасете с Kaggle и полученные результаты отправили. Вот что получилось:

Мы получили результат 0.9863, который поместил нас в топ 10% соревнования. Чтобы примерно понимать, какого уровня этот результат, скажем лишь, что человек, занявший первое место, получил денежное вознаграждение в размере $35000 с результатом 0.9885.
Читайте также: Как попасть в топ 2% соревнования Kaggle
Лучшие результаты были достигнуты в командах, состоящих из опытных и высококвалифицированных дата саентистов. Они использовали такие продвинутые техники, как ансамблинг моделей (ensembling), аугментацию данных (data augmentation), и затратили кучу времени в дополнении к тому, что мы делали до сих пор.
Мы реализовали модель для классификации по нескольким меткам при помощи мощной предобученной модели BERT. Как вы могли видеть, мы получили state-of-the-art результат на известных открытых данных. Таким образом, мы смогли построить первоклассную модель, имеющую применение в различных индустриях, в первую очередь, в области обслуживания клиентов.
Я советую вам реализовать эту модель на своих кастомных датасетах.
Jupyter-notebook для этой статьи доступен по ссылке.









Очень круто! Молодцы!
Спасибо что продвигаете цензуру, потом не удивляйтесь, когда этими алгоритмами будут затыкать рот.