
A real-time coherent video style transfer network – ReCoNet – is proposed by a group of researchers from the University of Hong Kong as a state-of-the-art approach to video style transfer. This is a feed-forward neural network that generates coherent stylized video at real-time speed. The process goes frame by frame through an encoder and a decoder. VGG loss network is responsible for capturing the perceptual style of the transfer target.
When compared to the other existing methods, ReCoNet demonstrates outstanding performance both quantitatively and qualitatively. So, let’s now discover, how the authors of this model were able to achieve high temporal consistency, fast processing speed, and nice perceptual style quality — all at the same time!
Suggested Approach
The novelty of their approach lies in introducing a luminance warping constraint in the output-level temporal loss. It allows to capture luminance changes of traceable pixels in the input video and increases stylization stability in the areas with illumination effects. Overall, this constraint is a key to suppressing temporal inconsistency. However, the authors also propose a feature-map-level temporal loss, which penalizes variations in high-level features of the same object in consecutive frames, and hence, further enhances temporal consistency on traceable objects.
ReCoNet Architecture
Let’s now discover the technical details of the suggested approach and study more carefully the network architecture, presented in Figure 1.
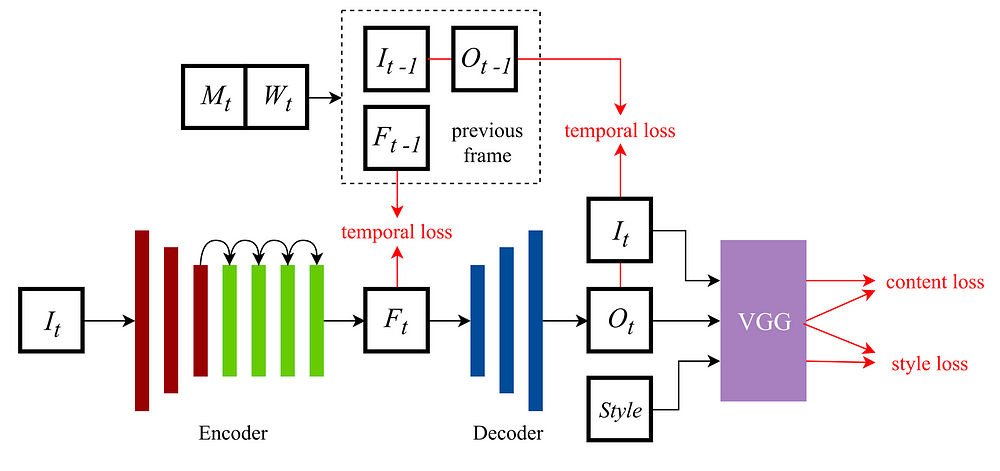
ReCoNet consists of three modules:
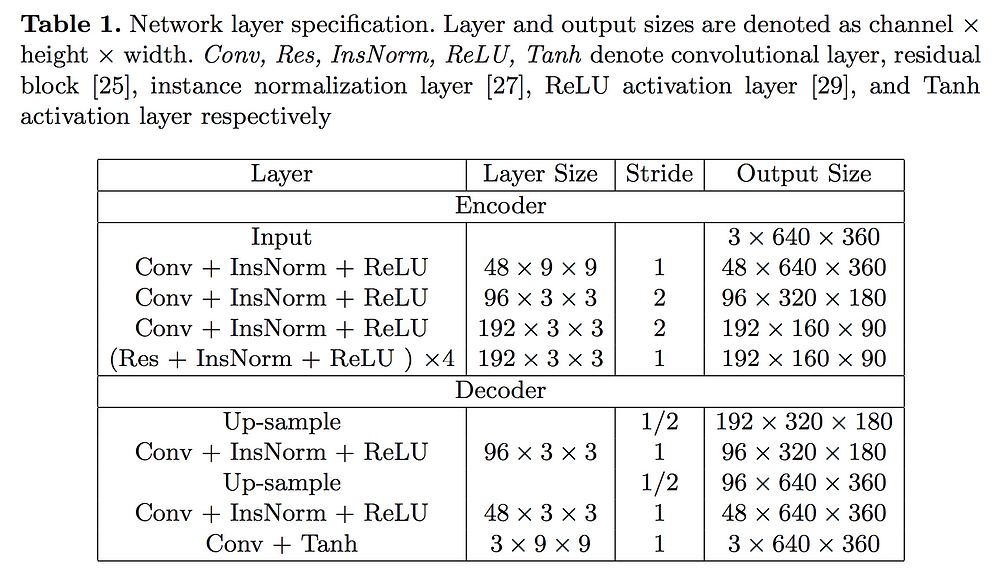
1. An encoder converts input image frames to encoded feature maps with aggregated perceptual information. There are three convolutional layers and four residual blocks in the encoder.
2. A decoder generates stylized images from feature maps. To reduce checkerboard artifacts, the decoder includes two up-sampling convolutional layers with a final convolutional layer instead of one traditional deconvolutional layer.
3. A VGG-16 loss network computes the perceptual losses. It is pre-trained on the ImageNet dataset.
Additionally, a multi-level temporal loss is added to the output of the encoder and the output of the decoder to reduce temporal incoherence.
In the training stage, a two-frame synergic training mechanism is carried out. This implies that for each iteration, the network generates feature maps and stylized output for two consecutive image frames in two runs. Note that in the inference stage, only one image frame is processed by the network in a single run. Yet, during the training, the temporal losses are computed using the feature maps and stylized output of both frames, and the perceptual losses are computed on each frame independently and summed up. The final loss function for the two-frame synergic training is:
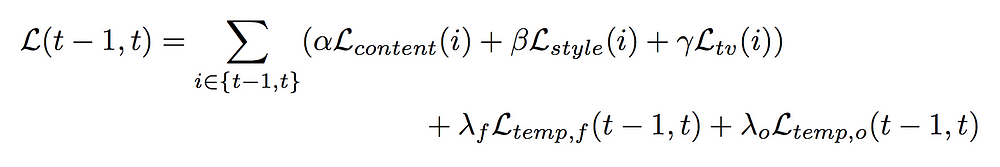
Results generated by ReCoNet
Figure 2 demonstrates how the suggested method transfers four different styles on three consecutive video frames. As you can see, ReCoNet successfully reproduces color, strokes, and textures of the style target and creates visually coherent video frames.


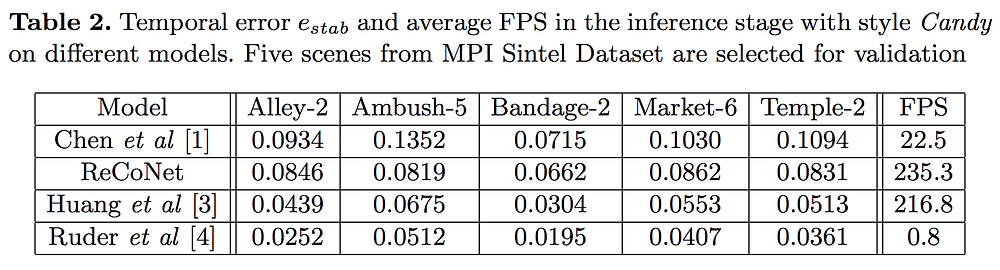
Next, the researchers carried out a quantitative comparison of ReCoNet’s performance against three other methods. The table below demonstrates temporal errors of four video transfer models on five different scenes. Ruder et al’s model demonstrates the lowest errors, but as you can see from its FPS parameter, it is not suitable for real-time usage due to the low inference speed. Huang et al’s model shows lower temporal errors than ReCoNet, but let’s turn to the qualitative analysis to see if this model is able to capture strokes and minor textures similarly to ReCoNet.
As obvious from the top row of Figure 3, Huang et al’s model fails to learn much about the perceptual strokes and patterns. This could be due to the fact that they use a low weight ratio between perceptual losses and temporal loss to maintain temporal coherence. In addition, their model uses feature maps from a deeper layer relu4_2 in the loss network to calculate the content loss, which makes it more difficult to capture low-level features such as edges.

The bottom row of Figure 3 shows that Chen et al’s work maintains well the perceptual information of both the content image and the style image. However, zoom-in regions reveal a noticeable inconsistency in their stylized results, as confirmed by higher temporal errors.
Interestingly, the models were also compared through a user study. For each of the two comparisons, 4 different styles were applied to 4 different video clips, and 50 people were asked to answer the following questions:
- Q1. Which model perceptually resembles the style image more, regarding the color, strokes, textures, and other visual patterns?
- Q2. Which model is more temporally consistent such as fewer flickering artifacts and consistent color and style of the same object?
- Q3. Which model is preferable overall?

The results of this user study, as shown in Table 3, validate the conclusions reached from the qualitative analysis: ReCoNet achieves much better temporal consistency than Chen et al’s model while maintaining similarly good perceptual styles; Huang et al’s model outperforms ReCoNet when it comes to temporal consistency, but is much worse in perceptual styles.
Bottom line
This novel approach to video style transfer performs great at generating coherent stylized videos in real-time processing speed while maintaining really nice perceptual style. The authors suggested using a luminance warping constraint in the output-level temporal loss and a feature-map level temporal loss for better stylization stability under illumination effects as well as better temporal consistency. Even though these constraints are effective in improving the temporal consistency of the resulted videos, ReCoNet is still behind some of the state-of-the-art methods when it comes to temporal consistency. However, considering its high processing speed and outstanding results in capturing perceptual information of both the content image and the style image, this approach is for sure at the forefront of video style transfer.




