Люди не запускают мыслительный процесс с нуля в каждый момент времени. Читая статью, вы понимаете смысл каждого слова на основе значений предыдущих слов. Мысли имеют свойство накапливаться и влиять друг на друга. Этот принцип используется в сетях LSTM.
Простые нейронные сети не могут этого сделать, и это серьезный недостаток. Представьте, что вы хотите в реальном времени классифицировать события, происходящие в фильме. Неясно, как обычная нейронная сеть может использовать знания о предыдущих событиях, чтобы изучить последующие.
Рекуррентные нейронные сети
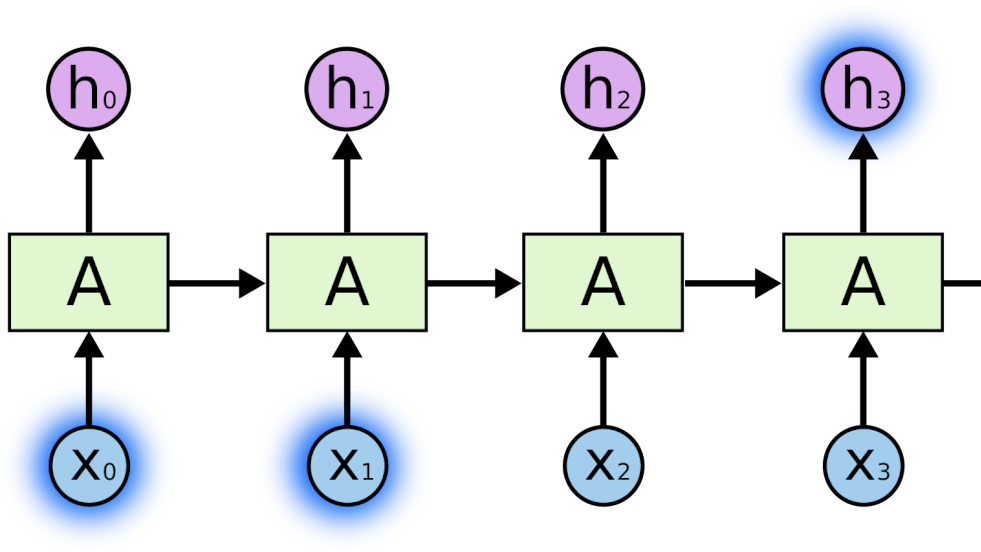
Рекуррентные нейронные сети (РНС) решают эту проблему. В них присутствуют циклы, сохраняющие информацию.

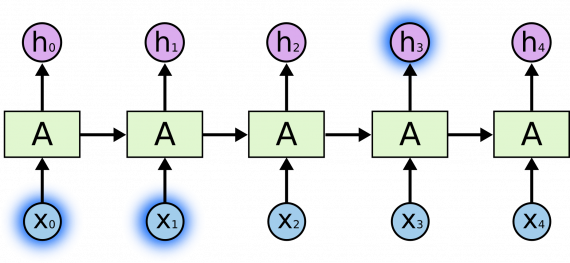
На приведенной выше диаграмме часть нейронной сети A принимает входной сигнал x и выводит значение h. Цикл позволяет передавать информацию с одного шага сети на другой.
Из-за наличия циклов РНС выглядят загадочно. Однако если подумать, становится понятно, что они не отличаются от простой нейронной сети. РНС можно представить как несколько копий одной и той же сети, каждый из которых передает сообщение преемнику. Рассмотрим, что произойдет, если мы выполним развертку цикла:
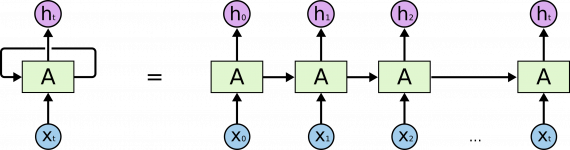
Развернутая структура РНС демонстрирует, что повторяющиеся нейронные сети тесно связаны с последовательностями и списками. Это естественная архитектура нейронной сети, используемая для данных такого типа.
И они, безусловно, используются! В последние годы достигнут невероятный успех в применении РНС к широкому кругу проблем: распознавание речи, лингвистическое моделирование, перевод, описание изображений… Этот список можно продолжить.
Существенным подспорьем в решении перечисленных задач стали LSTM — специфического типа рекуррентные нейронные сети, которые решают отдельные задачи гораздо эффективнее стандартных методов. С использованием сетей LSTM связаны все захватывающие результаты, основанные на РНС.
Проблема долгосрочных связей
Рекуррентная нейронная сеть используют полученную ранее информацию для решения последующих задач, например, уже полученные видеофрагменты для анализа последующих.
Иногда для решения задачи требуется просмотреть только последнюю информацию. Например, построить лингвистическую модель, которая пытается предсказать следующее слово, основываясь на предыдущих. Если мы пытаемся предсказать последнее слово в словосочетании «облака в небе», нам не нужен дополнительный контекст — очевидно, что следующее слово будет «небе». В тех случаях, когда разрыв между предыдущей информацией и местом, в котором она нужна, невелик, РНС справится с задачей.
Но иногда требуется больше контекста. Рассмотрим попытку предсказать последнее слово в тексте «Я вырос во Франции … Я свободно говорю на французском». Из предыдущих слов понятно, что следующим словом, вероятно, будет название языка, но если мы хотим назвать правильный язык, нужно учесть упоминание о Франции. Разрыв между необходимой для учета информацией и точкой, в которой она нужна, становится бОльшим.
К сожалению, по мере увеличения этого разрыва РНС теряют связь между информацией.
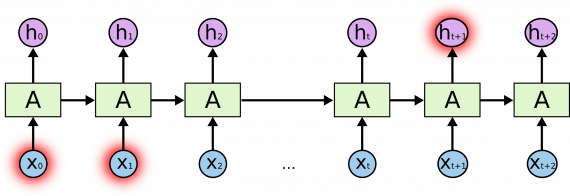
В теории РНС способны справиться с такими «долгосрочными зависимостями». Исследователь может тщательно подобрать параметры сети для устранения этой проблемы. К сожалению, на практике РНС не способны решить эту задачу. Проблема подробно исследована в работах [Hochreiter (1991)] и [Bengio, et al. (1994)], в которых выявлены фундаментальные ограничения РНС.
К счастью, у LSTM нет этой проблемы!
Сети LSTM
LSTM (long short-term memory, дословно (долгая краткосрочная память) — тип рекуррентной нейронной сети, способный обучаться долгосрочным зависимостям. LSTM были представлены в работе [Hochreiter & Schmidhuber (1997)], впоследствии усовершенствованы и популяризированы другими исследователями, хорошо справляются со многими задачами и до сих пор широко применяются.
LSTM специально разработаны для устранения проблемы долгосрочной зависимости. Их специализация — запоминание информации в течение длительных периодов времени, поэтому их практически не нужно обучать!
Все рекуррентные нейронные сети имеют форму цепочки повторяющихся модулей нейронной сети. В стандартных РНС этот повторяющийся модуль имеет простую структуру, например, один слой tanh.
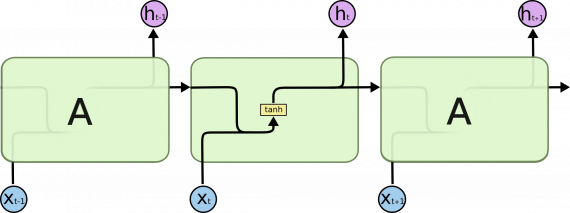
Не думайте о деталях, давайте просто постараемся запомнить обозначения, которые мы будем использовать.

На приведенной выше диаграмме каждая линия является вектором. Розовый круг означает поточечные операции, например, суммирование векторов. Под желтыми ячейками понимаются слои нейронной сети. Совмещение линий есть объединение векторов, а знак разветвления — копирование вектора с последующим хранением в разных местах.
Принцип работы LSTM сети
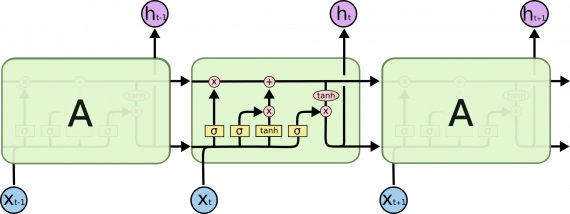
Ключевым понятием LSTM является состояние ячейки: горизонтальная линия, проходящая через верхнюю часть диаграммы.
Состояние ячейки напоминает конвейерную ленту. Оно проходит через всю цепочку, подвергаясь незначительным линейным преобразованиям.
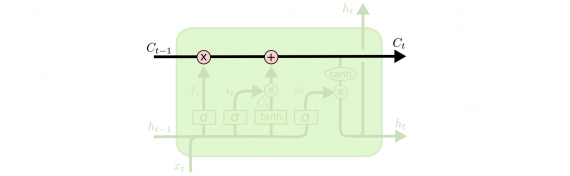
В LSTM уменьшает или увеличивает количество информации в состоянии ячейки, в зависимости от потребностей. Для этого используются тщательно настраиваемые структуры, называемые гейтами.
Гейт — это «ворота», пропускающие или не пропускающие информацию. Гейты состоят из сигмовидного слоя нейронной сети и операции поточечного умножения.
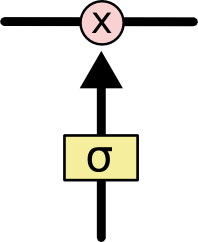
На выходе сигмовидного слоя выдаются числа от нуля до единицы, определяя, сколько процентов каждой единицы информации пропустить дальше. Значение «0» означает «не пропустить ничего», значение «1» — «пропустить все».
Пошаговая схема работы LSTM сети
LSTM имеет три таких гейта для контроля состояния ячейки.
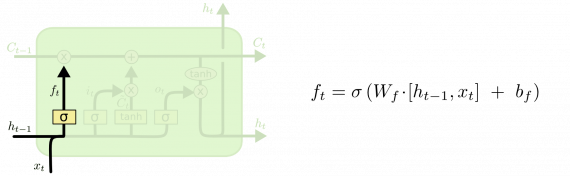
Слой утраты
На первом этапе LSTM нужно решить, какую информацию мы собираемся выбросить из состояния ячейки. Это решение принимается сигмовидным слоем, называемым «слоем гейта утраты». Он получает на вход h и x и выдает число от 0 до 1 для каждого номера в состоянии ячейки C. 1 означает «полностью сохранить», а 0 — «полностью удалить».
Вернемся к нашему примеру лингвистической модел. Попытаемся предсказать следующее слово, основанное на всех предыдущих. В такой задаче состояние ячейки включает языковой род подлежащего, чтобы использовать правильные местоимения. Когда появляется новое подлежащее, уже требуется забыть род предыдущего подлежащего.
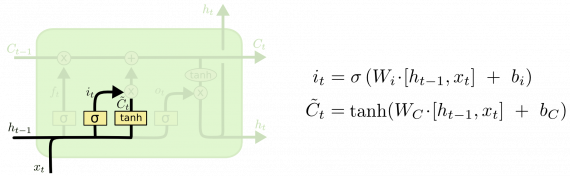
Слой сохранения
На следующем шаге нужно решить, какую новую информацию сохранить в состоянии ячейки. Разобьем процесс на две части. Сначала сигмоидный слой, называемый «слоем гейта входа», решает, какие значения требуется обновить. Затем слой tanh создает вектор новых значений-кандидатов C, которые добавляются в состояние. На следующем шаге мы объединим эти два значения для обновления состояния.
В примере нашей лингвистической модели мы хотели бы добавить род нового подлежащего в состояние ячейки, чтобы заменить им род старого.
Новое состояние
Теперь обновим предыдущее состояние ячейки для получения нового состояния C. Способ обновления выбран, теперь реализуем само обновление.
Умножим старое состояние на f, теряя информацию, которую решили забыть. Затем добавляем i*C. Это новые значения кандидатов, масштабируемые в зависимости от того, как мы решили обновить каждое значение состояния.
В случае с лингвистической моделью мы отбросим информацию о роде старого субъекта и добавим новую информацию.
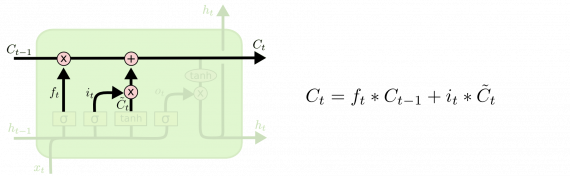
Наконец, нужно решить, что хотим получить на выходе. Результат будет являться отфильтрованным состоянием ячейки. Сначала запускаем сигмоидный слой, который решает, какие части состояния ячейки выводить. Затем пропускаем состояние ячейки через tanh (чтобы разместить все значения в интервале [-1, 1]) и умножаем его на выходной сигнал сигмовидного гейта.
Для лингвистической модели, так как сеть работала лишь с подлежащим, она может вывести информацию, относящуюся к глаголу. Например, сеть выведет информацию о том, в каком числе представлено подлежащее (единственное или множественное) для правильного спряжения глагола.
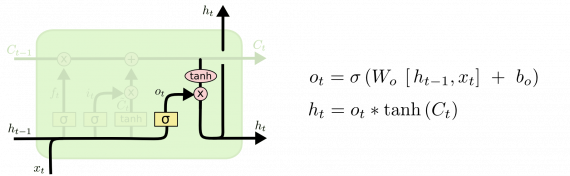
Примеры LSTM
Описанная выше схема — традиционная для LSTM. Но не все LSTM идентичны. На самом деле почти в каждой статье используются отличающиеся версии. Различия незначительны, но стоит упомянуть о некоторых из них.
В популярном варианте LSTM, представленном в [Gers & Schmidhuber (2000)], мы позволяем слоям гейтов просматривать состояние ячейки.
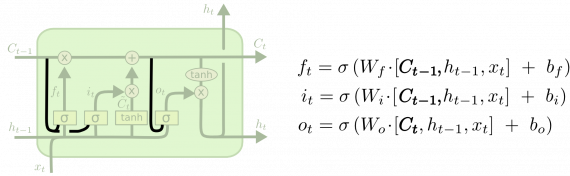
На диаграмме вверху «глазок» есть у всех гейтов, но во многих статьях он есть лишь у некоторых гейтов.
Другой вариант — использование связанных гейтов утраты и входа. Вместо того, чтобы отдельно решать, что забыть, а к чему добавить новую информацию, мы принимаем эти решения одновременно. Мы забываем информацию только тогда, когда нужно поместить что-то новое на том же месте. Новые значения вносятся в состояние только тогда, когда мы забываем что-то более старое.
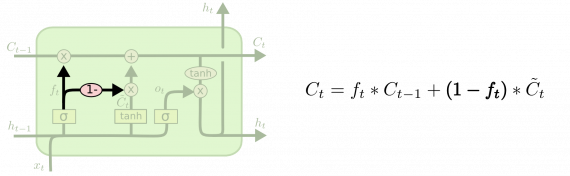
Несколько отличающейся пример LSTM — Gated Recurrent Unit или GRU, введенная в [Cho, et. al. (2014)]. Она объединяет гейты утраты и входа в единый «шлюз обновления». В нем также объединяются состояние ячейки и скрытое состояние и вносятся некоторые другие изменения. Получающаяся модель проще по сравнению со стандартными типами LSTM и становится все более популярной.

Это лишь некоторые из наиболее известных вариантов LSTM. Есть много других, таких как РНС с гейтом глубины (см. [Yao, et al. (2015)]). Известен также совершенно иной подход к решению долгосрочных зависимостей, приведенный в [Clockwork RNN by Koutnik, et al. (2014)].
Какой из перечисленных вариантов лучший? Имеют ли большое значение различия? В [Greff, et al. (2015)] приведено широкое сравнение популярных версий LSTM, а также продемонстрировано, что все они примерно одинаковы. В [Jozefowicz, et al. (2015)] опробованы более десяти тысяч архитектур РНС. Некоторые из них работают лучше LSTM при решении определенных задач.
Заключение
Представленные как набор уравнений, LSTM выглядят довольно устрашающе. Надеюсь, проход всей схемы шаг за шагом в этом посте сделало их немного более доступными.
LSTM были большим шагом в развитии РНС. Естественно задаться вопросом: а что, можно пойти дальше? Общее для исследователей мнение: «Да! Cледующий шаг заключается в использовании механизма внимания!» Идея состоит в том, чтобы РНС на каждом шаге выбирала информацию для просмотра из некого большего количества данных. Например, если вы используете РНС для создания описания изображения, сеть может выбрать часть изображения для просмотра каждого выводимого слова. Именно это и было проделано в [Xu, et al. (2015)] и станет отправной точкой для изучения механизма внимания.
Интересные статьи:
- Как работает сверточная нейронная сеть: архитектура, примеры, особенности
- Генеративно-состязательная нейросеть (GAN). Руководство для новичков
- Как создать собственную нейронную сеть с нуля на языке Python