Да, вы правильно прочитали, это правда HMTL — модель Hierarchical Multi-Task Learning, что дословно переводится как Иерархическое многозадачное обучение. Наблюдается нарастающая волна как в NLP, так и в целом в глубоком обучении, которая называется многозадачное обучение!
Перевод статьи Beating state-of-the-art in NLP with HMTL, автор — Victor Sanh.
Я работал с многозадачным обучением на протяжении года, и результатом работы является HMTL. Эта модель, которая превосходит современные state-of-the-art модели в некоторых задачах NLP, будет представлена на избирательной конференции AAAI. Была выпущена статья и представлен тренировочный код, которые стоит посмотреть.
Одна модель для нескольких задач
Дадим определение многозадачному обучению.
Многозадачное обучение — метод, в котором единственная архитектура обучается одновременно выполнять разные задачи.
Создана качественная онлайн демо-версия, в которой можно интерактивно взаимодействовать с HMTL. Попробуйте сами!
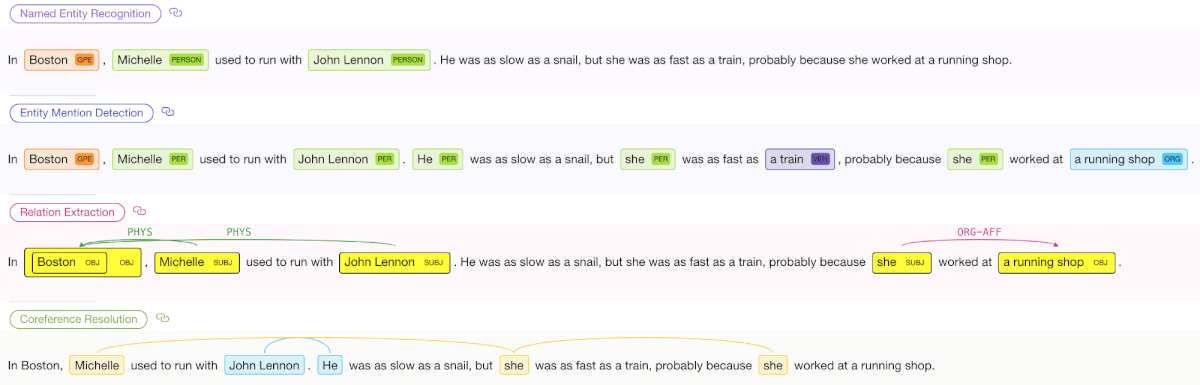
Традиционно, специальные модели обучались независимо для каждой из этих NLP задач (Named-Entity Recognition, Entity Mention Detection, Relation Extraction, Coreference Resolution).
В случае HMTL, все эти результаты получаются при помощи одной модели с одним прямым прохождением!
Но многозадачное обучение — это больше чем просто способ уменьшить количества вычислений заменой нескольких моделей на одну.
Многозадачное обучение (Multi-Task Learning, MTL) поощряет модели использовать признаки и методы, которые могут быть полезны в других задачах. Фундаментальная движущая сила MTL состоит в том, что близкие задачи должны получать преимущества друг от друга через индуцирование более богатых представлений.
Читайте также: Transfer learning с библиотекой Keras
Зачем применять многозадачное обучение
В классической парадигме машинного обучения мы обучаем одну модель через оптимизацию одной функции потери для выполнения одной конкретной задачи. Хотя фокусировка обучения на одном интересующем задании ещё является общим подходом для многих задач машинного обучения, это несет в себе недостатки. Такой способ никак не учитывает информацию, которую могут давать связанные (или почти связанные) задачи, чтобы добиться более точного результата.
Покажем сравнение с Усейном Болтом — возможно одним из самых великих спринтеров, девятикратным олимпийским золотым медалистом и обладателем нескольких действующих мировых рекордов (на ноябрь 2018 года). Так вот, великий бегун тренируется интенсивно и разнообразно, большую часть сил на тренировках затрачивая не на бег, а на другие упражнения. Усейн Болт, например, поднимает железо, запрыгивает на возвышенности, делает прыжки. Эти упражнения не связаны напрямую с бегом, но развивают силу мускулатуры и взрывную силу для улучшения главной задачи — спринта.
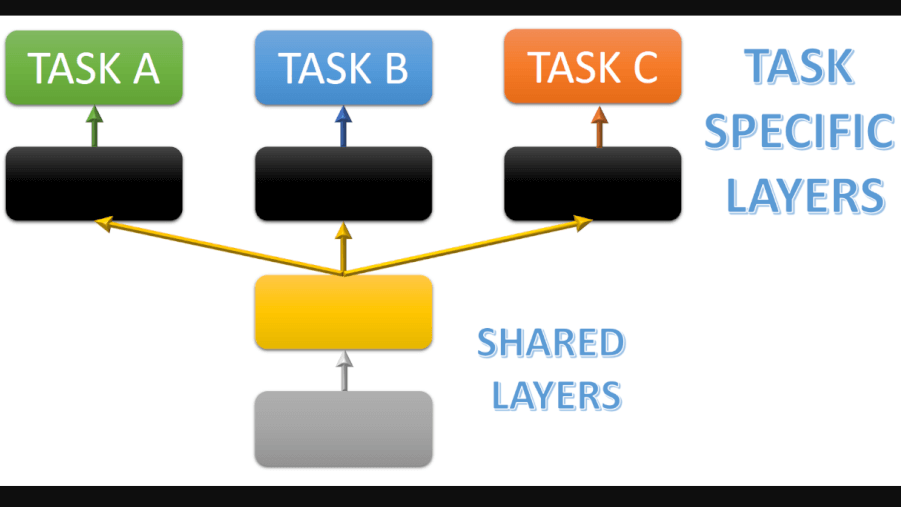
В естественной обработке языка MTL сначала был использован в подходах на нейронной основе исследователями R. Collobert и J. Weston. Модель, которую они предложили, представляла из себя MTL-инстанс, в котором несколько разных задач (со слоями для узкоспециализированных задач) основаны на одних и тех же общих вложениях, тренируемых для выполнения различных задач.
Совместное использование одного представления для выполнения разных задач может звучать как низкоуровневый способ передачи релевантной информации из одной задачи в другую. Однако такой способ оказался действительно полезным, как возможность улучшить обобщающую способность модели.
Хотя и можно заранее простым способом зафиксировать, как информация будет передаваться между задачами, мы можем также позволить модели самой решать, какие параметры и слои она должна делить (share), а также какие слои лучше всего использовать для данной задачи.
В последнее время идеи общих представлений вновь появились в значительной степени из-за погони за универсальными вложениями предложений, которые могут быть использоваться во всех областях независимо от конкретной задачи. Некоторые полагаются на MTL. Subramanian et al., например, заметил: для того чтобы иметь возможность обобщать широкий круг разнообразных задач, необходимо кодировать несколько лингвистических аспектов предложения. Была предложена Gensen — архитектура MTL с общим представлением кодировщика с несколькими последующими слоями для конкретных задач. В этой работе использовались 6 различных слабо связанных задач — от поиска логических выводов из естественного языка до машинного перевода через разбор грамматики с фразовыми структурами.
Коротко говоря, многозадачное обучение сейчас привлекает к себе много внимания и становится обязательным для широкого спектра задач не только в естественной обработке языка, но и в компьютерном зрении. Совсем недавно бенчмарки, такие как GLUE benchmark (оценка общего понимания языка), были представлены для оценки обобщающей способности архитектур MTL и, в более общем смысле, моделей понимания языка (Language Understanding).
Многозадачное обучение на Python
Теперь давайте напишем код, чтобы увидеть как работает MTL на практике.
Очень важная часть программы многозадачного обучения — тренировка. Здесь необходимо ответить на вопросы:
- как обучать нейросеть;
- в каком порядке решать различные задачи;
- должны ли все задачи обучаться за одинаковое количество эпох.
По этим вопросам нет единого мнения, в литературе встречается много вариаций обучения.
Для начала давайте начнем с простой и общей части кода, которой будут безразличны обучающие процессы:
- Выбираем задачу (независимо от выбора алгоритма);
- Выбираем пакет (batch) в датасете для выбранной задачи (случайная выборка пакета — почти всегда хороший выбор);
- Выполним прямой проход через нейросеть;
- Распространим ошибку в обратном направлении.
Этих четырех шагов должно быть достаточно в большинстве случаев.
Во время прямого прохождения модель считает потери в интересующей задаче. Во время же обратного прохождения — подсчитанные из функции потерь градиенты распространяются по сети, чтобы одновременно оптимизировать как слои для конкретных задач, так и общие (и все остальные релевантные обучаемые параметры).
На сайте Hugging Face представлена хорошая библиотека AllenNLP, разрабатываемая Институтом ИИ Аллена. Эта библиотека — мощный и в то же время гибкий инструмент для проведения исследований в NLP. AllenNLP совмещает в себе гибкость PyTorch с умными модулями для загрузки и обработки данных, которые тщательно разрабатывались для задач NLP.
Если вы еще не заглянули туда, я настоятельно рекомендую сделать это. Команда разработчиков сделала замечательное учебное пособие по использованию библиотеки.
Код
Ниже я представлю простую часть кода для создания обучающей модели MTL на основе AllenNLP.
Давайте сначала представим класс Task, который будет содержать датасеты для конкретных задач и связанные с ними атрибуты.
Теперь, когда у нас есть класс Task, мы можем определить нашу модель Model.
Создание модели в AllenNLP — весьма простое занятие. Для этого нужно просто сделать ваш класс наследуемым от класса allennlp.models.model.Model. В этом случае будет автоматически получено множество методов, таких как get_regularization_penalty(), который будет штрафовать модель (То есть L1 или L2 регуляризация) во время обучения.
Давайте поговорим о двух основных методах, которые мы будем использовать в работе сети, это forward() и get_metrics(). Эти методы во время обучения рассчитывают, соответственно, прямое прохождение (вплоть до вычисления потерь) и метрики обучения/оценки для данной задачи.
Важный элемент в многозадачном обучении — добавить конкретный аргумент task_name, который во время обучения будет использоваться для выбора текущей интересующей задачи. Давайте посмотрим, как это написать:
Ключевой пункт в MTL — выбор порядка выполнения (обучения) задач. Самый простой способ сделать это — производить выбор задачи случайно из равномерного распределения после каждого обновления параметров (прямой + обратный проход через нейросеть). Такой алгоритм использовался в нескольких ранних работах, таких как упомянутый ранее Gensen.
Однако мы можем поступить несколько умнее. Давайте выбирать задачу случайным образом, учитывая распределение вероятности, в котором каждая вероятность выбора задачи пропорциональна отношению количества пакетов (training batch) для задачи к общему числу пакетов. Как мы увидим позже, такая схема случайного выбора оказывается весьма полезной и является элегантным способом предотвратить забывание (catastrophic forgetting — явление в искусственных нейронных сетях, которое описывает потерю выученной ранее информации при получении новой информации).
В следующем куске кода реализована процедура выбора задачи. Здесь task_list определяется как список задач Task, на которых мы хотим обучать нашу модель.
Давайте запустим нашу MTL модель.
Следующий кусок кода показывает, как можно собрать все ранее созданные элементарные части.
Итерации метода train() будут проходить по задачам в соответствии с их распределением вероятности. Метод также будет оптимизировать параметры MTL модели шаг за шагом.
Хорошей идеей будет добавить условие остановки во время обучения на основе валидационных метрик (_val_metric и _val_metric_decreases в классе Task). Например, можно останавливаться, когда валидационная метрика не улучшается в течение patience количества эпох. Такое условие проверяется после каждой тренировочной эпохи. Хотя мы этого не делали, вы должны легко разобраться, как модифицировать представленный код, чтобы он принимал во внимание это улучшение. В любом случае, здесь можно посмотреть на полный тренировочный код.
Существуют другие приемы, которые вы можете использовать в обучении модели MTL. Многие из них не были освещены в этой статье, но вы можете найти больше информации по ссылкам. Ниже представлены основные идеи способов дальнейшего улучшения модели:
- Последовательная регуляризация. Одна из основных проблем во время обучения MTL модели — забывание. Модель полностью или частично забывает часть информации, связанную с обучением прошлой задачи, после обучения новой задачи. Это явление повторяется вновь и вновь, когда несколько задач выполняются последовательно. Hashimoto et al. представляет последовательную регуляризацию: она предотвращает слишком сильное по сравнению с прошлыми эпохами обновление параметров при помощи добавления L2 штрафа к функции потерь. В таком конфигурации тренер MTL не меняет задачу после обновления параметров, а проходит полный тренировочный датасет интересующей задачи.
- Многозадачное обучение как вопросно-ответная система. Недавно McCann et al. [7] представил новую парадигму в исполнении многозадачного обучения. Каждая задача переформулируется в вопросно-ответную задачу, а единственная модель (MQAN) обучается совместно отвечать на 10 разных задач, рассмотренных в этой работе. MQAN достигает state-of-the-art результатов в нескольких задачах, например, в таких WikiSQL — задача семантического парсинга. Вообще говоря, в этой работе обсуждаются ограничения монозадачного обучения и связи многозадачного обучения с Transfer Learning.
Улучшение state-of-the-art в семантических задачах: Модель иерархического многозадачного обучения (HMTL)
Мы уже поговорили о тренировочной схеме, теперь стоит ответить на вопрос, как мы можем создать модель, которая будет получать наибольшую пользу от этой схемы многозадачного обучения.
В недавней работе, представленной на AAAI в январе, было предложено сконструировать такую модель в виде иерархии. Если говорить более подробно, мы строим иерархию между набором точно подобранных семантических задач, чтобы отразить лингвистические иерархии между разными задачами (здесь также полезно посмотреть Hashimoto et al.).
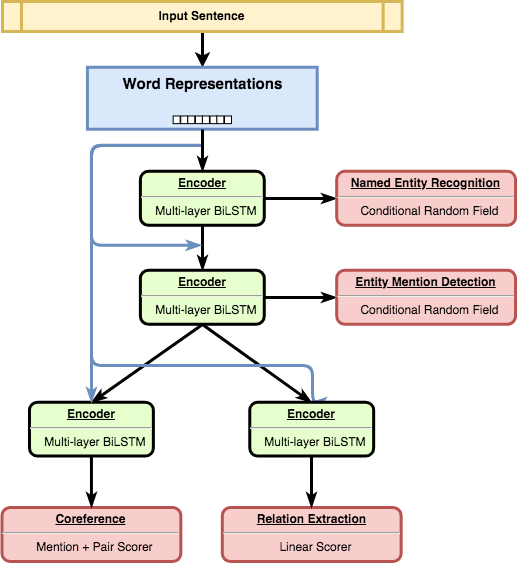
За иерархической структурой модели стоит следующий смысл. Некоторые задачи могут быть простыми и требовать ограниченного количества модификаций исходных данных, в то время как другие могут требовать больше знаний (knowledge) и более сложную обработку входных данных.
Мы рассматриваем набор, состоящих их следующих семантических задач:
- Named Entity Recognition;
- Entity Mention Detection;
- Relation Extraction;
- Coreference Resolution.
Модель иерархически организована так, как показано на рисунке. Простые задачи решаются на нижних уровнях нейронной сети, а более сложные — в её глубоких слоях.
В нашем эксперименте мы установили, что эти задачи могут получать друг от друга преимущества с помощью многозадачного обучения:
- Комбинация упомянутых 4 задач приводят к state-of-the-art результатам на 3 из них (Named Entity Recognition, Relation Extraction and Entity Mention Detection);
- Фреймворк MTL значительно ускоряет скорость обучения по сравнению с фреймворками монозадачного обучения.
Мы также проанализировали обучаемые и совместно используемые вложения в HMTL. Для анализа использовался SentEval — набор из 10 пробных задач, представленных Conneau et al. [8]. Эти пробные задания нацелены на оценку способности распознавать широкий набор лингвистических свойств (синтаксические, поверхностные и семантические).
Анализ показывает, что общие вложения нижних уровней кодируют богатое представление. По мере движения от нижних к верхним слоям модели скрытые состояния слоев имеют тенденцию представлять более сложную семантическую информацию.