
Глубокое обучение требует больших вычислительных ресурсов, поэтому очень важно, какой графический процессор (видеокарту) вы выберете для своих исследований. Надежный GPU позволит быстро вычислять оптимальные архитектуры и настройки глубоких сетей, и проводить эксперименты за дни вместо месяцев, часы вместо дней, минуты вместо часов.
Перевод статей A Full Hardware Guide to Deep Learning и Which GPU(s) to Get for Deep Learning, автор — Tim Dettmers. Ссылка на оригинал — в подвале статьи.
О том, как найти компромисс между стоимостью и производительностью в облачных GPU читайте здесь: Сравнение Cloud GPU для машинного обучения
Выбор GPU
Три основные ошибки, которые обычно делаются при выборе видеокарты:
- высокая цена/низкая производительность;
- недостаточый объем памяти;
- плохое охлаждение.
В целом, требования к памяти следующие:
- Для исследования, в котором нужна максимальная производительность: > = 11 ГБ
- Для поиска новых архитектур: > = 8 ГБ
- Любое другое исследование: 8 ГБ
- Kaggle: 4 — 8 ГБ
- Стартапы: 8 ГБ (но проверьте конкретную область применения для размеров модели)
- Компании: 8 ГБ для прототипирования, > = 11 ГБ для обучения
Другая проблема, на которую стоит обратить внимание, особенно если вы покупаете несколько RTX-карт, это охлаждение. Если вы хотите вставить GPU в слоты PCIe, которые расположены рядом друг с другом, вы должны убедиться, что получаете GPU с вентилятором. В противном случае процессоры будут перегреваться, работать медленнее (примерно на 30%) и умирать быстрее.
Стоит ли использовать несколько видеокарт?
Использование нескольких видеокарт позволит увеличить скорость обучения, поэтому имеет смысл, если у вас есть на это деньги.
Для сверточных нейронных сетей можно ожидать ускорения в 1,9x/2,8x/3,5x для 2/3/4 графических процессоров.
Для рекуррентных сетей длина последовательности является наиболее важным параметром, а для распространенных проблем NLP можно ожидать аналогичного или несколько худшего ускорения, чем для сверточных сетей.
Полносвязные сети обычно имеют низкую производительность для параллелизма данных, и для ускорения необходимы более совершенные алгоритмы.
Еще одно преимущество использования нескольких GPU, даже если вы не распараллеливаете алгоритмы, заключается в том, что вы можете запускать несколько экспериментов отдельно на каждом графическом процессоре. Вы не получаете ускорения, но получаете больше информации о производительности, используя различные алгоритмы или параметры одновременно.
Это очень полезно, если ваша главная цель — как можно быстрее получить опыт обучения сети. Это полезно и для исследователей, которые хотят попробовать несколько версий нового алгоритма одновременно.
Что один графический процессор делает быстрее другого?
Лучший показатель производительности графического процессора — комбинация пропускной способности, FLOPS и Tensor Cores.
Чтобы углубить ваше понимание и помочь сделать осознанный выбор, расскажу о том, какие части аппаратного обеспечения ускоряют работу GPU для двух наиболее важных тензорных операций: перемножения матриц и свертки.
Простой и эффективный способ думать о матричном умножении — это то, что оно ограничено пропускной способностью. То есть пропускная способность памяти является наиболее важной особенностью GPU, если вы хотите использовать LSTM и другие рекуррентные сети, которые выполняют многократное умножение матриц.
Для сверточных нейронных сетей имеет значение скорость обучения. Таким образом, TFLOP на графическом процессоре — лучший показатель производительности ResNet и других сверточных архитектур.
Тензорные сердечники слегка меняют уравнение. Это очень простые специализированные вычислительные блоки, которые могут ускорить вычисления — но не пропускную способность памяти — и, таким образом, наибольшее преимущество можно увидеть для сверточных сетей, которые с тензорными ядрами быстрее примерно на 30-100% .
В целом, правило выбора GPU для машинного обучения следующее:
- смотрите на показатели пропускной способности, если вы работаете с RNN;
- смотрите на показатели FLOPS, если вы работаете со сверткой;
- используйте тензорные ядра, если можете себе позволить.
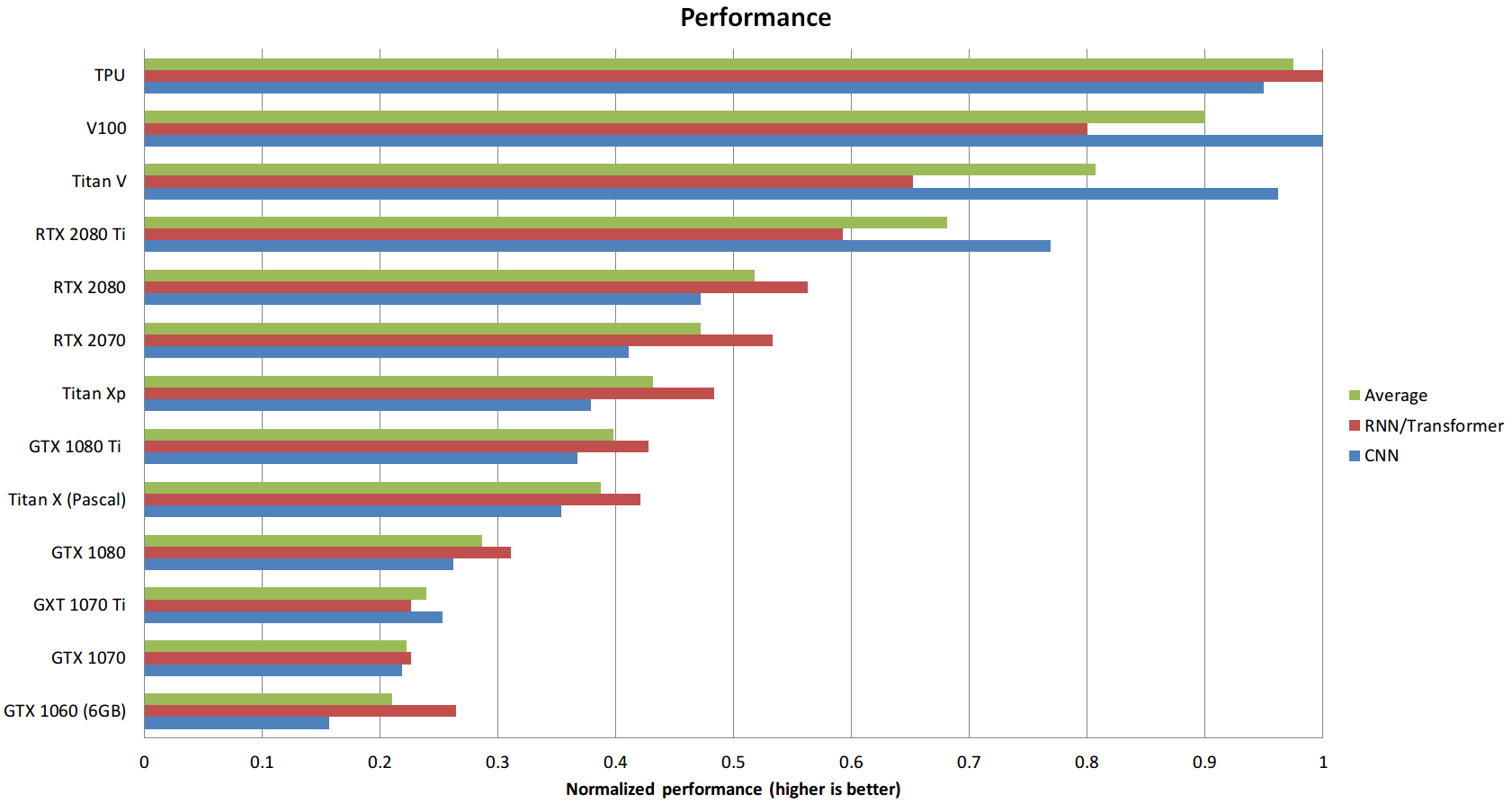
Производительность/стоимость
Экономическая эффективность графического процессора, вероятно, наиболее важный критерий выбора. Я провел анализ эффективности затрат, который включал пропускную способность памяти, TFLOP и Tensor Cores. Я посмотрел цены на eBay и Amazon и взвесил их 50:50, а затем посмотрел на показатели эффективности для LSTM, CNN с и без тензорных ядер. Я взял эти показатели производительности и усреднил их, чтобы получить средние оценки производительности, с помощью которых я затем рассчитал показатели производительности/стоимости. Вот результат:
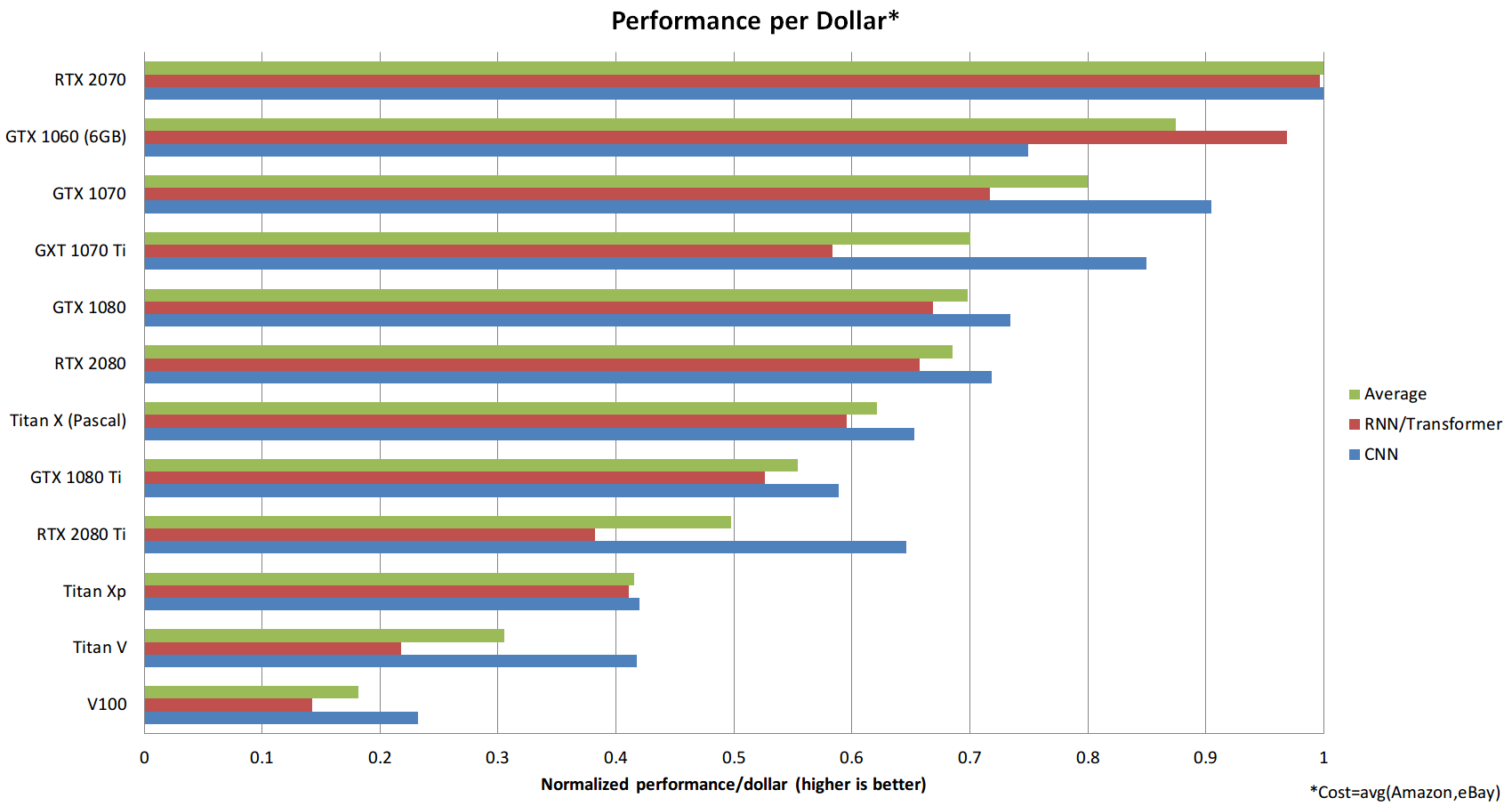
Из этих данных видно, что RTX 2070 является более экономичным, чем RTX 2080 или RTX 2080 Ti. Почему это так? Способность выполнять 16-битные вычисления с Tensor Cores намного более ценна, чем просто наличие большого количества тензорных ядер. С RTX 2070 вы получаете эти функции по самой оптимальной цене.
Этот анализ также имеет определенные отклонения, которые следует учитывать:
- Цены колеблются. В настоящее время цены карты GTX 1080 Ti, RTX 2080 и RTX 2080 Ti кажутся завышенными, но в будущем они могут стать более разумными.
- Анализ не учитывает, сколько памяти вам нужно и сколько GPU вы можете разместить на своем компьютере. Один компьютер с 4 быстрыми GPU намного экономичнее двух компьютеров с самыми оптимальными картами.
Заключение
Я вижу две основные стратегии, которые имеют смысл: выбрать графический процессор серии RTX 20, чтобы получить быстрое обновление, или выбрать дешевый графический процессор серии GTX 10 и обновить его, как только RTX Titan станет доступен.
Если вы менее серьезно относитесь к производительности или она просто не нужна вам, например, в случае с Kaggle и прототипированием, вы можете значительно выиграть от дешевых графических процессоров серии GTX 10. При этом, если вы выбираете графический процессор серии GTX 10, будьте осторожны, чтобы объем памяти графического процессора соответствовал вашим требованиям.
Читайте: Как попасть в топ 2% соревнования Kaggle
Общие рекомендации по выбору GPU
Лучший GPU в целом: RTX 2070.
Следует избегать: любая карта Tesla; любая карта Quadro; любая карта Founders Edition; Titan V, Titan XP.
Рентабельно, но дорого: RTX 2070.
Рентабельно и дешево: GTX Titan (Pascal) с eBay, GTX 1060 (6GB), GTX 1050 Ti (4GB).
У меня мало денег: GTX Titan (Pascal) с eBay, или GTX 1060 (6 ГБ), или GTX 1050 Ti (4 ГБ).
У меня почти нет денег: GTX 1050 Ti (4 ГБ); CPU (прототипирование) + AWS / TPU (обучение); или Colab.
Я участвую в Kaggle: RTX 2070. Если вам не хватает денег, выберите GTX 1060 (6 ГБ) или GTX Titan (Pascal) c eBay для создания прототипов и AWS для окончательного обучения. Используйте библиотеку fastai.
Я работаю с технологиями компьютерного зрения или машинного перевода: GTX 2080 Ti с конструкцией вентилятора; Обновление до RTX Titan в 2019 году.
Я — исследователь NLP: RTX 2070.
Я начал углубленное изучение глубокого обучения и я серьезно к этому отношусь: начните с RTX 2070. В зависимости от того, какую область вы выберете дальше (стартап, Kaggle, исследования, прикладное глубокое обучение), продадите свой графический процессор и купите что-нибудь более подходящее примерно через два года.
Я хочу попробовать глубокое обучение, но я не серьезно: GTX 1050 Ti (4GB) или 1050 (2GB).






Выбрал себе 1660. Посмотрим на что способна.