DreamX-World 1.0: открытая модель генерации мира с контролем камеры, текстовым управлением и запоминанием локаций
17 июня 2026

DreamX-World 1.0: открытая модель генерации мира с контролем камеры, текстовым управлением и запоминанием локаций
Команда AMAP-ML опубликовала DreamX-World 1.0 — интерактивную генеративную модель мира, которая превращает текст или изображение в управляемое видео с точным контролем камеры, памятью о ранее посещённых сценах и поддержкой событий…
VibeThinker: 3B-модель рассуждает и кодит на уровне флагманских моделей
16 июня 2026

VibeThinker: 3B-модель рассуждает и кодит на уровне флагманских моделей
Команда Sina Weibo AI опубликовала VibeThinker-3B — компактную языковую модель всего с 3 миллиардами параметров, которая на задачах верифицируемых рассуждений (математика, программирование, STEM) вплотную приближается к результатам флагманских моделей DeepSeek…
ESM Cambrian: модель для предсказания и дизайна белков превзошла AlphaFold3 от Google и построила крупнейший атлас белкового мира
4 июня 2026

ESM Cambrian: модель для предсказания и дизайна белков превзошла AlphaFold3 от Google и построила крупнейший атлас белкового мира
Команда исследователей из Biohub опубликовала ESM Cambrian (ESMC) — языковую модель для предсказания и дизайна белков, которая обошла AlphaFold3 от Google по точности предсказания структур, спроектировала молекулы, которые крепко связываются…
LLaVA-OneVision-2-8B: мультимодальная модель анализирует сжатый видеопоток через кодек вместо нарезки кадров
28 мая 2026

LLaVA-OneVision-2-8B: мультимодальная модель анализирует сжатый видеопоток через кодек вместо нарезки кадров
Исследователи из Glint Lab, AIM for Health Lab и MVP Lab опубликовали LLaVA-OneVision-2 (LLaVA-OV-2) — мультимодальную модель нового поколения, которая переосмысливает то, как нейросеть «смотрит» видео. Вместо того чтобы нарезать видео…
LongLive-2.0: NVIDIA научила модель генерировать длинное видео в реальном времени с квантованием NVFP4
20 мая 2026

LongLive-2.0: NVIDIA научила модель генерировать длинное видео в реальном времени с квантованием NVFP4
Исследователи из NVIDIA опубликовали LongLive-2.0 — инфраструктуру для обучения и запуска моделей генерации длинного видео с использованием квантования до 4-битной точности NVFP4. Квантование — это сжатие весов модели за счёт…
OpenAI Codex: полный гайд по установке и начале работы на 2026 год, плюсы и минусы агента
18 мая 2026

OpenAI Codex: полный гайд по установке и начале работы на 2026 год, плюсы и минусы агента
За последние два года AI-инструменты для разработки успели пройти путь от «умного автодополнения» до полноценных агентных систем. Если ранние Copilot-подобные решения в основном помогали дописывать код строчка за строчкой, то…
SenseNova-U1: мультимодальная архитектура NEO-unify работает напрямую с пикселями без VAE
14 мая 2026

SenseNova-U1: мультимодальная архитектура NEO-unify работает напрямую с пикселями без VAE
Команда SenseNova представила новую мультимодальную архитектуру SenseNova-U1, которая объединяет понимание изображений, генерацию и редактирование внутри единого трансформера без отдельного визуального энкодера и вариационного автокодировщика. Такой подход убирает необходимость постоянно переводить…
Claude Code: полное руководство по установке и начале работы
8 мая 2026

Claude Code: полное руководство по установке и начале работы
Claude Code — агентный инструмент для разработки от Anthropic, который работает прямо в терминале или десктопном приложении. В отличие от инструментов автодополнения, он действует на уровне всего проекта: читает файлы,…
OpenSeeker-v2: лучший в своем классе Deep Research агент, созданный академической командой всего на 10600 примерах
7 мая 2026

OpenSeeker-v2: лучший в своем классе Deep Research агент, созданный академической командой всего на 10600 примерах
Исследователи из Шанхайского университета Цзяо Тун доказали, что для создания лучшего в своём классе deep research агента не нужны сотни миллиардов токенов предобучения и дорогостоящее обучение с подкреплением. Достаточно 10…
OpenGame: ИИ-агент создает браузерные 2D-игры с нуля по текстовому описанию
22 апреля 2026

OpenGame: ИИ-агент создает браузерные 2D-игры с нуля по текстовому описанию
Команда исследователей из CUHK MMLab опубликовала OpenGame — первый агентный фреймворк для создания браузерных 2D-игр по текстовому описания. Проект полностью открытый: код фреймворка, веса модели GameCoder-27B и датасеты доступны на…
ChatGPT Images 2.0: OpenAI запустила обновление модели генерации изображений с рассуждениям, 2K-разрешением и мультиязычным текстом
22 апреля 2026

ChatGPT Images 2.0: OpenAI запустила обновление модели генерации изображений с рассуждениям, 2K-разрешением и мультиязычным текстом
21 апреля 2026 года OpenAI выпустила ChatGPT Images 2.0 на базе модели gpt-image-2. По данным LM Arena, новая модель сразу заняла первое место во всех категориях генерации изображений с отрывом…
ClawGUI: первый открытый фреймворк полного цикла для GUI-агентов от обучения до реального устройства
15 апреля 2026

ClawGUI: первый открытый фреймворк полного цикла для GUI-агентов от обучения до реального устройства
Исследователи из Чжэцзянского университета опубликовали ClawGUI — полностью открытый фреймворк для разработки GUI-агентов, которые управляют приложениями через визуальный интерфейс, как это делает человек: касаниями, свайпами и вводом текста. На практике…
ClawBench: лучший ИИ-агент смог успешно завершить только 33% реальных повседневных задач
13 апреля 2026
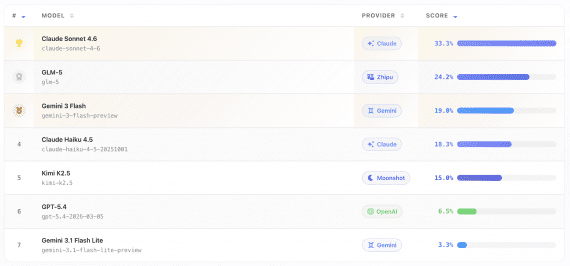
ClawBench: лучший ИИ-агент смог успешно завершить только 33% реальных повседневных задач
ClawBench — бенчмарк, который проверяет, могут ли ИИ-агенты выполнять настоящие повседневные задачи в интернете: забронировать рейс, откликнуться на вакансию, оформить заказ. Результаты показали, что даже сильнейшая модель — Claude Sonnet…
InCoder-32B-Thinking: открытая модель генерации кода для микроконтроллеров, оптимизации GPU-ядер и RTL-проектирования
7 апреля 2026

InCoder-32B-Thinking: открытая модель генерации кода для микроконтроллеров, оптимизации GPU-ядер и RTL-проектирования
Команда исследователей из Пекинского авиационного института, Шанхайского транспортного университета, Университета Манчестера и компании IQuest Research опубликовала InCoder-32B-Thinking — языковую модель с расширенной цепочкой рассуждений (chain-of-thought reasoning) для задач разработки кода…
Trinity-Large-Thinking 400B: масшабная открытая reasoning-модель для агентных задач стоит в 28 раз дешевле Claude Opus-4.6
3 апреля 2026

Trinity-Large-Thinking 400B: масшабная открытая reasoning-модель для агентных задач стоит в 28 раз дешевле Claude Opus-4.6
Компания Arcee AI выложила в открытый доступ Trinity-Large-Thinking — модель с рассуждениями для сложных многоходовых агентных задач. На PinchBench — главном бенчмарке для агентных задач — она занимает второе место…
PixelSmile: открытая модель для редактирования эмоций на изображениях с плавным контролем интенсивности эмоций
31 марта 2026
PixelSmile: открытая модель для редактирования эмоций на изображениях с плавным контролем интенсивности эмоций
Исследователи из Fudan University и StepFun опубликовали PixelSmile — диффузионную модель для точного редактирования мимики на портретах и аниме-изображениях. Вместо обучения на дискретных метках, например, «страх/не страх», модель использует непрерывные…
RealRestorer: открытая модель улучшения качества фото обогнала Nano Banana Pro на бенчмарке с реальными снимками
30 марта 2026

RealRestorer: открытая модель улучшения качества фото обогнала Nano Banana Pro на бенчмарке с реальными снимками
Команда исследователей из StepFun, Southern University of Science and Technology и Китайской академии наук опубликовала RealRestorer — открытую модель улучшения качества фотографий, которая умеет убирать размытость, шум, дождь, засветку от…
MinerU-Diffusion: новый подход к OCR через диффузионное декодирование ускоряет парсинг PDF в 3 раза без потери точности
27 марта 2026

MinerU-Diffusion: новый подход к OCR через диффузионное декодирование ускоряет парсинг PDF в 3 раза без потери точности
Команда из Shanghai Artificial Intelligence Laboratory и Пекинского университета опубликовала MinerU-Diffusion — фреймворк для распознавания текста в документах (OCR), который отказывается от классической авторегрессивной генерации в пользу диффузионного декодирования. Проект…
daVinci-MagiHuman: открытая 15B-модель генерирует 5-секундное видео с липсинком за 2 секунды на одном H100
24 марта 2026

daVinci-MagiHuman: открытая 15B-модель генерирует 5-секундное видео с липсинком за 2 секунды на одном H100
Команды SII-GAIR и Sand.ai опубликовали daVinci-MagiHuman — открытую мультимодальную 15B-модель на основе однопоточного трансформера, которая одновременно генерирует видео с липсинком и синхронное аудио и создает 5-секундный клип в 256p за…
OpenClaw: лобстер, который захватил мир. ИИ-агент работает локально и управляется через мессенджеры
18 марта 2026

OpenClaw: лобстер, который захватил мир. ИИ-агент работает локально и управляется через мессенджеры
OpenClaw — открытый ИИ-агент, созданный австрийским разработчиком Питером Штайнбергером в ноябре 2025 года. ИИ-агент — это программная оболочка вокруг языковой модели, которая не просто генерирует текст в ответ на запрос,…
OpenClaw-RL: ИИ-агент учится на собственных ошибках через реакции пользователя и среды, обновляя веса на ходу
17 марта 2026

OpenClaw-RL: ИИ-агент учится на собственных ошибках через реакции пользователя и среды, обновляя веса на ходу
Исследователи из Princeton University предложили фреймворк OpenClaw-RL, позволяющий ИИ-агенту улучшаться в режиме реального времени — без отдельного этапа сбора данных и без ручной разметки. Большинство RL-фреймворков для языковых моделей работают…