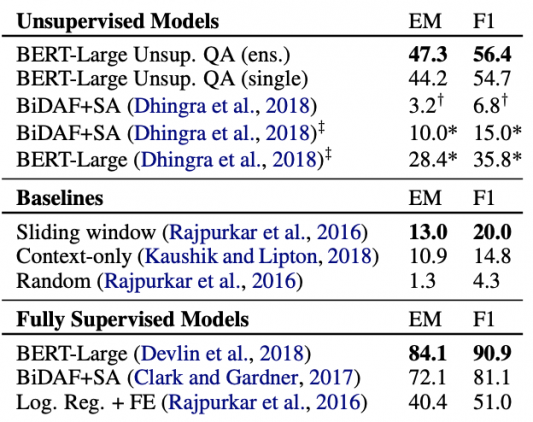
Исследователи обучили и сравнили state-of-the-art модели для генерации ответов на вопросы. Ключевое отличие моделей — отсутствие необходимости в размеченных данных. Исследователи генерируют вопросы для обучения моделей с помощью нейросети. Разметка данных для обучения модели является ресурсоемким процессом. Unsupervised модели работают генерируют сравнимые по качеству ответы с supervised моделями. Без использования размеченного датасета (SQuAD) для обучения F1-метрика топ-1 модели равна 56.4. В случае, когда ответ — это именованная сущность, F1 лучшей модели равен 64.5. Unsupervised подходы выдают результаты лучше, чем ранние supervised методы.
Про задачу
Задача экстрактивной вопросно-ответной системы (extractive QA) — это популярная подсфера обработки естественного языка. Модель в такой задаче должны вычленить из документа короткий кусок текста, который отвечает на поставленный вопрос. Несмотря на то, что модели обучения с учителем хорошо справляются с задачей, они требуют тысяч или сотен тысяч размеченных примеров для обучения. Это также выливается в снижение качества модели, когда она тестируется на документах, которые не похожи на те, на которых она обучалась. Цель исследования — рассмотреть экстрактивный QA как self-supervised задачу. Модель, которую предложили исследователи, обходит ранние модели обучения с учителем на задаче SQuAD. При этом модель не требует размеченных данных при обучении. Код проекта был опубликован в репозитории на GitHub.
Как это работает
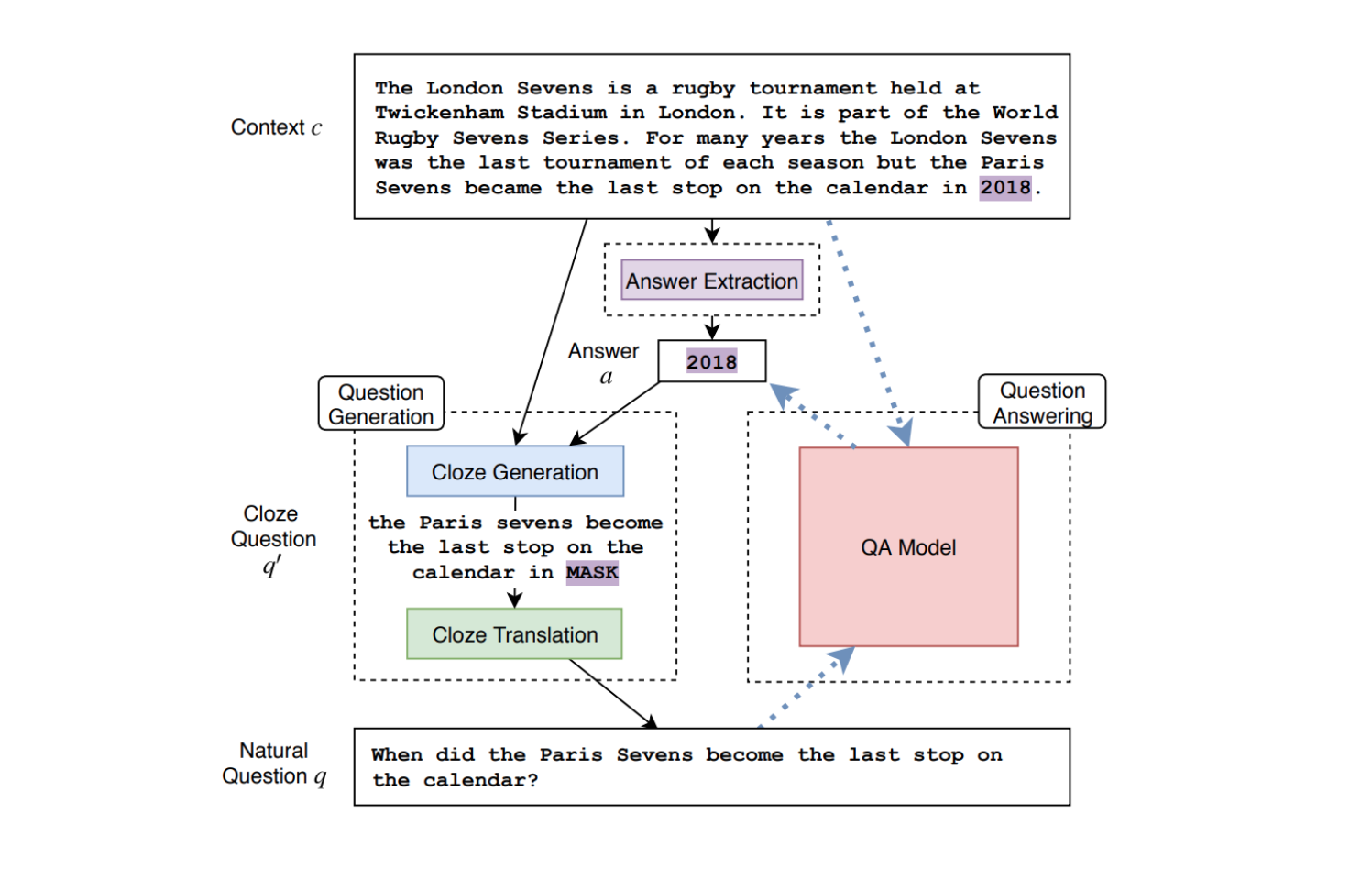
Процесс обучения нейросети состоит из двух шагов. Сначала обучается модель, которая заполняет пустые места в документе (cloze questions). Эта часть также не требует обучения с учителем. Модель в первую очередь определяет потенциальные ответы из текста, а затем формулирует cloze вопрос. Это вопрос дальше переформулировывается в вопрос на естественном языке.
Например, модели поступает на вход следующий текст:
“The Broncos took an early lead in Super Bowl 50 and never trailed. […] Denver linebacker Von Miller was named Super Bowl MVP, recording five solo tackles, two and a half sacks, and two forced fumbles.”
Система может выделить “Broncos,” “Denver” или числа как потенциальные ответы. Для ответа “Broncos,” cloze вопрос является “The _____ took an early lead in Super Bowl 50 and never trailed,”. Этот cloze вопрос конвертируется в вопрос на естественном языке: “Who took an early lead in Super Bowl 50?”
На втором шаге берется стандартная архитектура для экстрактивного QA, которая обычно требует размеченных данных. Вместо обучающей выборки используются сгенерированные вопросы и ответы из модели на первом шаге.
Какую модель выбрать
Чтобы оценить подход, исследователи использовали датасет SQuAD и метрику F1. Ниже видно, что из unsupervised моделей лучше всего себя показал BERT-Large трансформер.