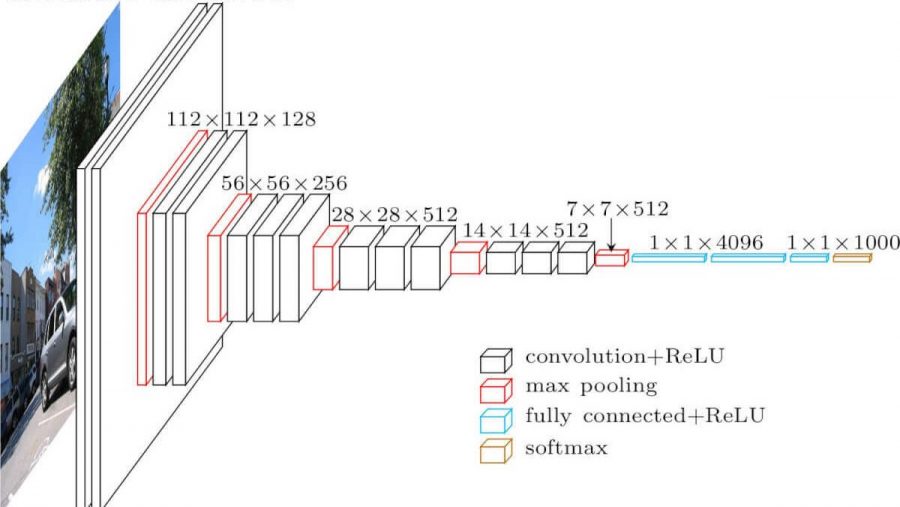
VGG16 — модель сверточной нейронной сети, предложенная K. Simonyan и A. Zisserman из Оксфордского университета в статье “Very Deep Convolutional Networks for Large-Scale Image Recognition”. Модель достигает точности 92.7% — топ-5, при тестировании на ImageNet в задаче распознавания объектов на изображении. Этот датасет состоит из более чем 14 миллионов изображений, принадлежащих к 1000 классам.
VGG16 — одна из самых знаменитых моделей, отправленных на соревнование ILSVRC-2014. Она является улучшенной версией AlexNet, в которой заменены большие фильтры (размера 11 и 5 в первом и втором сверточном слое, соответственно) на несколько фильтров размера 3х3, следующих один за другим. Сеть VGG16 обучалась на протяжении нескольких недель при использовании видеокарт NVIDIA TITAN BLACK.
Датасет
ImageNet — набор данных, состоящий из более чем 15 миллионов размеченных высококачественных изображений, разделенных на 22000 категорий. Изображения были взяты из интернета и размечены вручную людьми-разметчиками с помощью краудсорсинговой площадки Mechanical Turk от Amazon.
В 2010 году, как часть Pascal Visual Object Challenge, началось ежегодное соревнование — ImageNet Large-Scale Visual Recognition Challenge (ILSVRC). В ILSVRC используется подвыборка из ImageNet размером 1000 изображений в каждой из 1000 категорий. Таким образом, тренировочный сет состоял из примерно 1.2 миллионов изображений, проверочный — 50000 изображений, тестовый — 150000 изображений. Так как ImageNet состоит из изображений разного размера, то их необходимо было привести к единому размеру 256х256. Если изображение представляет из себя прямоугольник, то оно масштабируется и из него вырезается центральная часть размером 256х256.
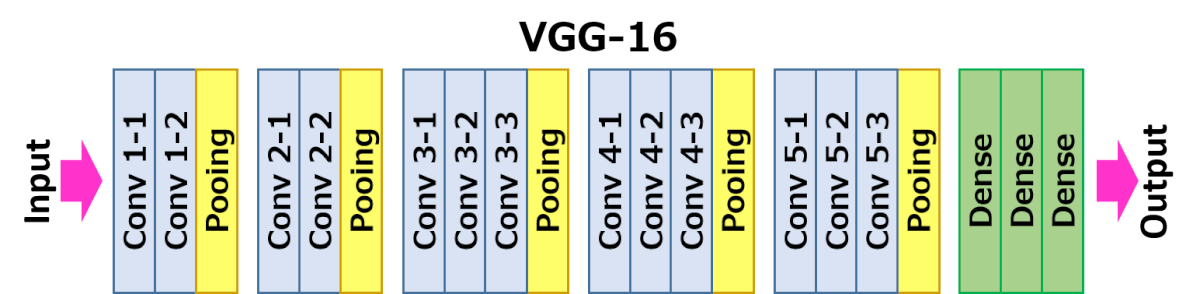
Архитектура VGG16
Архитектура VGG16 представлена на рисунке ниже.
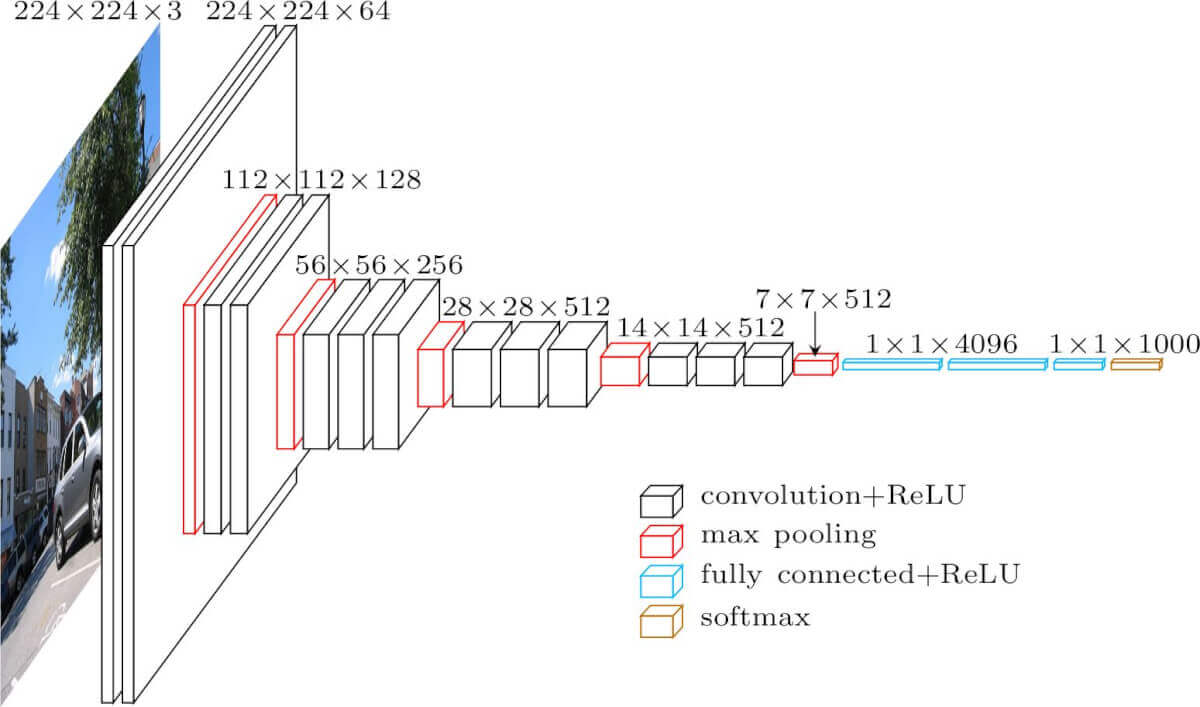
На вход слоя conv1 подаются RGB изображения размера 224х224. Далее изображения проходят через стек сверточных слоев, в которых используются фильтры с очень маленьким рецептивным полем размера 3х3 (который является наименьшим размером для получения представления о том,где находится право/лево, верх/низ, центр).
В одной из конфигураций используется сверточный фильтр размера 1х1, который может быть представлен как линейная трансформация входных каналов (с последующей нелинейностью). Сверточный шаг фиксируется на значении 1 пиксель. Пространственное дополнение (padding) входа сверточного слоя выбирается таким образом, чтобы пространственное разрешение сохранялось после свертки, то есть дополнение равно 1 для 3х3 сверточных слоев. Пространственный пулинг осуществляется при помощи пяти max-pooling слоев, которые следуют за одним из сверточных слоев (не все сверточные слои имеют последующие max-pooling). Операция max-pooling выполняется на окне размера 2х2 пикселей с шагом 2.
После стека сверточных слоев (который имеет разную глубину в разных архитектурах) идут три полносвязных слоя: первые два имеют по 4096 каналов, третий — 1000 каналов (так как в соревновании ILSVRC требуется классифицировать объекты по 1000 категориям; следовательно, классу соответствует один канал). Последним идет soft-max слой. Конфигурация полносвязных слоев одна и та же во всех нейросетях.
Все скрытые слои снабжены ReLU. Отметим также, что сети (за исключением одной) не содержат слоя нормализации (Local Response Normalisation), так как нормализация не улучшает результата на датасете ILSVRC, а ведет к увеличению потребления памяти и времени исполнения кода.
Конфигурация
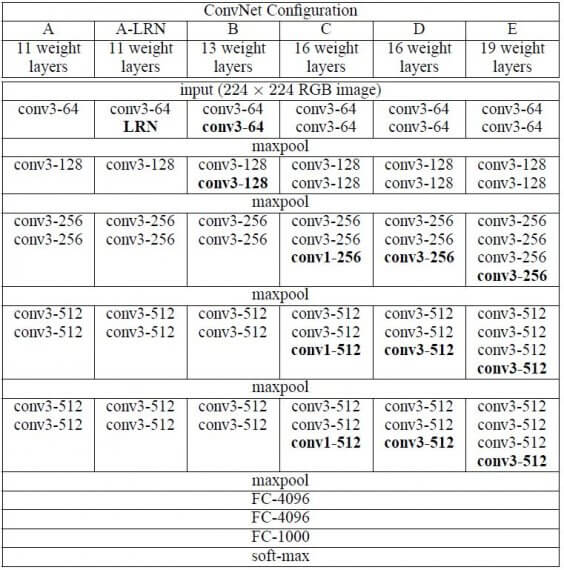
Конфигурации сверточных сетей представлены на рисунке 2. Каждая сеть соответствует своему имени (A-E). Все конфигурации имеют общую конструкцию, представленную в архитектуре, и различаются только глубиной: от 11 слоев с весами в сети A (8 сверточных и 3 полносвязных слоя) до 19 (16 сверточных и 3 полносвязных слоя). Ширина сверточных слоев (количество каналов) относительно небольшая: от 64 в первом слое до 512 в последнем с увеличением количества каналов в 2 раза после каждого max-pooling слоя.
Реализация
К сожалению, сеть VGG имеет два серьезных недостатка:
- Очень медленная скорость обучения.
- Сама архитектура сети весит слишком много (появляются проблемы с диском и пропускной способностью)
Из-за глубины и количества полносвязных узлов, VGG16 весит более 533 МБ. Это делает процесс развертывания VGG утомительной задачей. Хотя VGG16 и используется для решения многих проблем классификации при помощи нейронных сетей, меньшие архитектуры более предпочтительны (SqueezeNet, GoogLeNet и другие). Несмотря на недостатки, данная архитектура является отличным строительным блоком для обучения, так как её легко реализовать.
[Pytorch]
[Keras]
Результаты
VGG16 существенно превосходит в производительности прошлые поколения моделей в соревнованиях ILSVRC-2012 and ILSVRC-2013. Достигнутый VGG16 результат сопоставим с победителем соревнования по классификации (GoogLeNet с ошибкой 6.7%) в 2014 году и значительно опережает результат Clarifai победителя ILSVRC-2013, который показал ошибку 11.2% с внешними тренировочными данными и 11.7% без них. Что касается одной сети, архитектура VGG16 достигает наилучшего результата (7.0% ошибки на тесте), опережаю одну сеть GoogLeNet на 0.9%.
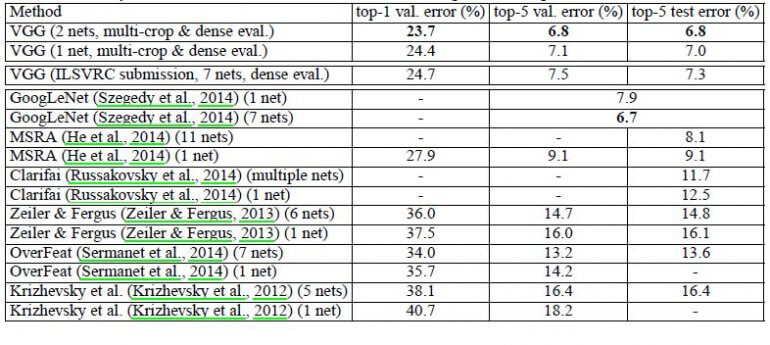
Было показано, что глубина представления положительно влияет на точность классификации, и state-of-the-art результат на соревновательном датасете ImageNet может быть достигнут с помощью обычной сверточной нейронной сети с значительно большей глубиной.








Ddkewsfr. 190531040Z+8:=7egkggrdddasM. 79GVGRjk66Gygyhjessxdfgggtttgftggggg